The Von Neumann Model
- The input device is used to load programs and data into memory.
- The CPU fetches program instructions from memory, processing the data and generating results.
- The results are sent to an output device.
Systems
The CPU is connected to the rest of the components by the system bus and is driven by the clock. If any component wants to interrupt the CPU’s current task then it can send an interrupt.
graph TD
Clock --> CPU
CPU --- SB[System Bus]
SB --- mem[Memory Subsystem]
SB --- io1[I/O Device]
SB --- io2[I/O Device]
SB --- io3[I/O Device]
io1 --> Interrupts
io2 --> Interrupts
io3 --> Interrupts
Interrupts --> CPU
CPU
The CPU fetches instructions from main memory and executes them.
The instructions it executes are very basic:
- Move a value.
- Add 2 numbers.
Different types of CPU have different instruction sets.
In this course we will use intel x86 assembly.
The internal activity of the CPU is synchronised to a fast clock.
System Bus
The bus is a collection of connections allowing communication between the various components on the motherboard.
This is much simpler than a point-to-point system as all components share the same connection.
The sender places an item/message on the bus, to be taken off by the receiver.
The bus may be split into:
- Address lines
- Used to specify a memory address to be accessed.
- Data Lines
- Used to carry a value to be transferred.
- Control Lines
- Tell the receiver what to do.
In modern systems there are several interconnected buses (SATA, PCIe, USB).
If multiple components want to communicate at the same time then you run into an issue of bus contention.
I/O Devices
These include any device that can input or output data to the system. These can include peripherals or sensors inside the system.
To find whether devices are ready the following are options:
- Polling
- Inefficient
- Not a good use of CPU time.
- Interrupts
- The device sends a signal when it is ready.
- An interrupt handler is invoked by the interrupt.
Memory
All programs and data must be converted to binary form and brought into the computer memory prior to being processed. (stored program concept)
Memory can be:
- RAM
- Volatile random access memory.
- ROM
- Non-volatile read only memory.
- Used to hold system boot code.
- Flash
- Read and write, non-volatile.
Can be thought of as a sequence of words. A word is 4 bytes of memory. (32-bit)
Each word holds its own content and has its own unique address.
Most modern systems are bytes addressable.
Words, Bytes & Bits
-
A word is formed from one or more bytes.
-
Individual bits are zero indexed from right to left.
-
Bit zero may be referred to as the least significant bit (lsb).
- At the other end is the msb.
The CPU
This is a block diagram of a CPU:
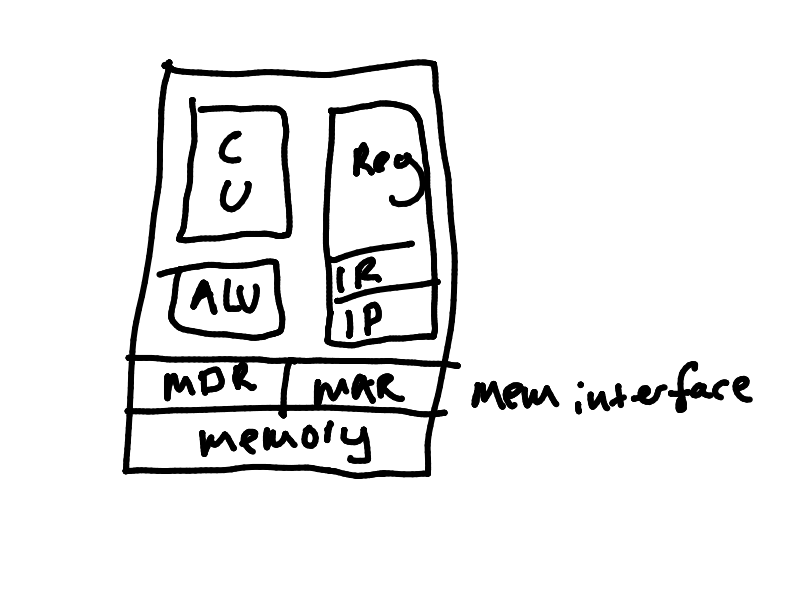
- CU - Control Unit
- Fetches instructions and works out what to do with them.
- Controls the flow of execution.
- ALU - Arithmetic Logic Unit
- Performs operations on bit patterns in order to complete mathematical and logic operations.
- Registers
- Memory on the CPU die.
- General purpose registers
- IR - Instruction Register
- Always holds the address of the next instruction being executed.
- IP - Instruction Pointer
- Contain memory addresses.
- Memory Interface
- MAR - Memory Address Register
- Stores the address of an area of memory to be addressed.
- MDR - Memory Data Register
- Stores a word of memory to/from the RAM.
The Fetch-Execute Cycle
The control unit continually direct the fetching and execution of instructions in a cycle.
- Copy address contained in the IP to the MAR. Issue read request to memory.
- Increment IP to point to next instruction. (Add word size e.g. 4/8)
- Instruction will arrive in MDR. Copy it to IR.
- Decode IR to work out what is required.
- Fetch any operands.
- Carry out execution.
- Go to step 1.
Steps 5 and 6 may cause further memory accesses.
A Typical Instruction Set
- Data Transfer
- Arithmetic
- Add, subtract, multiply, divide.
- Logical
- AND, OR, NOT, shift rotate.
- Test and Compare
- Control Flow
- Conditional jump, unconditional jump, subroutine call and return.
- Other
All high-level language code must be translated into these basic machine code instructions.
The difference between machine code and assembly are that machine code are the bytes that the CPU reads. Assembly is 1 to 1 with machine code but gives the instructions names and allows you to give memory addresses names.
Opcode
Specifies the operation to be performed.
Operand Specifiers
The locations of source operands and destinations for results.
Often one of the operand will act as both source and destination.

Addressing Modes
The locations of operands are specified using addressing modes:
- Immediate
- The operand value is encoded directly into the instruction.
- Register
- The operand resides in a CPU register.
- Direct
- The operand resides in main memory; the instruction encodes its address.
- Register Indirect
- The instruction specifies a register, which in turn holds the address of the operand.
Generating Instructions
The machine code for high level languages is made by a compiler.
HLL Translation Process
graph LR
Editor --> SP[Source Program]
SP --> Compiler
Compiler --> OC[Object Code]
OC --> Linker
LM[Library Modules] --> Linker
Linker --> EP[Executable Program]
The compiler analyses the source code, checks for certain types of error, and generate equivalent object code.
The user’s code is integrated with pre-compiled library routines by a linker to form final the executable.
A single HLL statement may convert to many low-level instructions.
This process allows making human readable code that can run on the CPU.
Writing machine code direct in binary would be too difficult and error prone. However we can do it using something called assembly language.
Each assembly language statement corresponds to a single machine instruction.
Opcodes are specified using mnemonics (jmp, mov)
Registers are given names and addresses are specified using labels.
Labels can also be used to label lines of code to jump to.
Single Line Example
adjust: mov eax, num1 ; Moves num1 to eax
- A label can refer to the address of an instruction or the address of a data item.
- Statements like this can be translated to binary by a program called an assembler.
- It may also be possible to use and in-line assembler.
- Allows insertion of assembly code into HLL programs.
- Advantage of mix and match.
Intel x86 Registers
The x86 also has a number of general purpose registers:
EAX: Accumulator RegisterEBX: Base RegisterECX: Counter RegisterEDX: Data Register
Other such as the Flags register and ESP register will be considered later.
Even though the registers have names they are general purpose so can be used for anything.
The Accumulator
Most CPUs have an accumulator. This is a register for a general purpose data storage and computation. On an x86 CPU it looks like this:
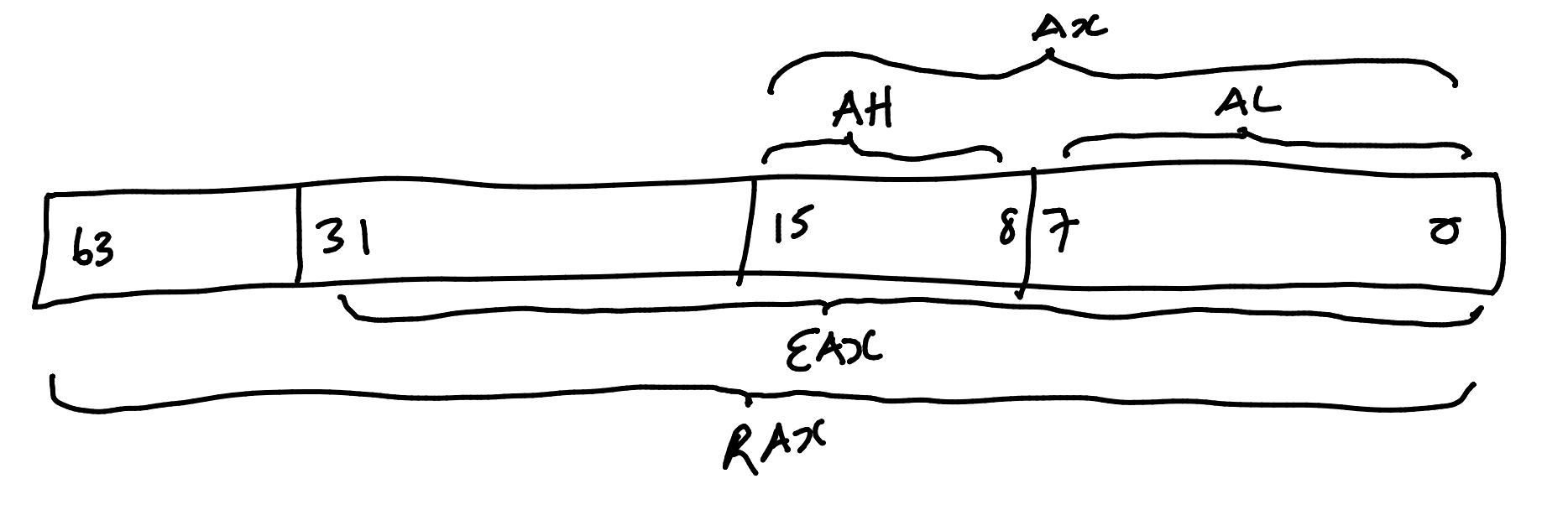
As the word size of x86 has increased over time so have the registers. To handle backwards compatibility each word size has a different name.
Register and Opcode Examples
mov eax, 42 ; Put 42 into eax.
mov ax, count ; Get 16-bit variable.
mov al, 'x' ; Put ASCII val of 'x' in low byte.
inc eax ; Add one to eax.
add eax, 10 ; Add 10 to eax.
mov sum, eax; Store 32-bit var.
Note that the first operand acts as the destination.
Note that mov var, var is not allowed.
Assignment
We can now handle assignment:
num = count1 + count2 - 10
The equivalent in asm would be:
mov eax, count1
add eax, count2
sub eax, 10
mov num, eax
This transfers count1 to the accumulator and then adds count2 to the accumulator. 10 is then subtracted from the accumulator and the result is transferred to the label num.
The Flags Resgister
We often want to query the effect of a previous instruction. The status of an operation is recorded in the flags register.
It contains these flags and others:
- S - Sign
- Indicates whether result is +/-.
- Z - Zero
- Indicates if result is zero or not.
- C - Carry
- Indicates an arithmetic carry.
- O - Overflow
- Arithmetic overflow error.
We can use these flags in conjunction with jump instructions to control program flow.
Jump Instructions
The simplest form is the unconditional jump. Is has the syntax:
JMP <address of the target instruction>
The address of the target instruction is usually given as a label.
Example
start: ...
...
jmp continue ; jump forwards
...
...
jmp start ; jump backwards
...
...
continue:
Jumping is unrestricted, so programmers must take care to avoid spaghetti code.
Conditional Jumps
Conditional jumps make the jump only if a specified condition holds.
If the condition is false, execution “falls through” to the next instruction.
Jumps that Test Flags
| Instruction |
Jumps if |
Value |
| JC |
Carry flag is set |
1 |
| JNC |
Carry flag is clear |
0 |
| JZ |
Zero flag is set |
1 |
| JNZ |
Zero flag is clear |
0 |
| JS |
Sign flag is set |
1 |
| JNS |
Sign flag is not set |
0 |
| JO |
Overflow flag is set |
1 |
| JNO |
Overflow flag is not set |
0 |
Example
num = num - 10;
if (num == 0) {
num = 100;
}
The prior code would look like this in assembly:
mov eax, num
sub eax, 10
jnz store
mov eax, 100
store:
mov num, eax
You can see that we should test if not zero in the assembly code such that the body of the if is executed if the branch doesn’t take place.
Comparing Values
The cmp instruction is the most common way of comparing two values, prior to a conditional jump.
Internally, it subtract one value from the other, without altering the operands.
It does modify the status flags.
Hence if eax and ebx contain the same values, then:
will set the Z flag.
Example
Suppose our program reads a single letter command from the user into the al register.
The command q is used to quit the program.
graph TD
1[cmp al, 'q'] --> z["Z (flags register)"]
z --> j[jz end]
Other Conditional Jumps
These jumps can be used in combination with the cmp instruction.
| Instruction |
Jumps if (after using cmp) |
| JE |
The first operand (in cmp) is equal to the second operand. |
| JNE |
The first and second operands are not equal. |
| JG/JNLE |
First operand is greater. |
| JLE/JNG |
First operand is less or equal. |
| JL/JNGE |
First operand is less. |
| JGE/JNL |
First operand is greater or equal. |
if Statements
if (c > 0)
pos = pos + c;
else
neg = neg + c;
This will convert to the following assembly:
mov eax, c
cmp eax, 0 ; compare c to 0
jg positive ; jump to positive if positive
negative: ; else negative
add neg, eax
jmp endif ; jump over positive
positive:
add pos, eax
endif:
...
Iteration can be achieved by jumping backwards in the code.
We need to ensure that we don’t end up in an infinite loop. A while loop simply repeat while a given condition is true.
while Loops
This codes calculates the 1000th Fibonacci number:
while (fib2 < 1000) {
fib0 = fib1;
fib1 = fib2;
fib2 = fib1 + fib0;
}
This is the equivalent assembly code:
while1:
mov eax, fib2
cmp eax, 1000 ; compare for condition
jge end_while ; jump out of loop if condition is met
mov eax, fib1
mov fib0, eax
mov eax, fib2
mov fib1, eax
add eax, fib0
mov fib2, eax
jmp while1 ; jump back to start of loop
end_while:
...
do-while Loops
This is the same code using a do-while loop:
do {
fib0 = fib1;
fib1 = fib2;
fib2 = fib1 + fib0;
} while (fib2 < 1000);
And the same code in assembly:
do-while:
mov eax, fib1
mov fib0, eax
mov eax, fib2
mov fib1, eax
add eax, fib0
mov fib2, eax
cmp eax, 1000
jl do-while
end_while:
...
This code is more efficient than the last implementation as fib2 is already in the accumulator for the comparison.
for Loops
A counting loop can be implemented in almost exactly the same way as a while loop:
for (int x = 1; x <= 10; x++) {
y = y + x;
}
Attempt 1
mov eax, 1 ; use eax as x var
floop: ; start of for loop
add y, eax ; update y
inc eax ; x++
cmp eax, 10
jle floop ; end when eax = 11
Attempt 2
We can improve by counting in reverse:
mov eax, 10 ; start at 10
floop: ; start of for loop
add y, eax ; update y
dec eax ; x--
jnz floop ; end at zero
Attempt 3 - ecx and loop
The ecx register is the counter register and often used in loops.
In can be used iwth special jump instructions:
- JECXZ - Jump is
ecx is zero.
- JCXZ - Jump is
cx is zero.
It can also be used with the loop instruction:
loop <lab> ; decrement ecx
; jump to <lab> if ecx not zero
So, general form to repeat a statement $n$ times:
mox ecx, n
L1: code for statement
loop L1
This would give the following for the example:
mov ecx, 10 ; use ecx as x var
floop:
add y, ecx ; update y
loop floop ; loop back to floop if ecx not zero
This saves another instruction.
Using Local Variables
Variables will be declared in the C portion of the code and take up the following amount of space:
int - 4 byteschar - 1 byte
- Strings will take as many bytes and characters.
Example of Common Assignments
int num = 0;
signed in num = -2;
char alpha = 'a';
char name[] = "Jo Smith\n";
In this example the string must end with \n in order to print the next statement on the next line.
\n has the decimal value of 10.
Every variable is just a location in memory at which a value is stored. Pointers will refer to the value of a memory location but sometimes we want it’s address.
Variable Addresses in Assembly
In assembly language we can get the address of a variable with the LEA (load effective address) instruction.
We often use the base register, ebx:
We can access the value pointed to by using the register indirect addressing mode:
Using square brackets will treat the value as an address and fetch the value from that address.
Arrays
An array is just a sequence of values, stored consecutively in memory.
Array Storage
Different data types many occupy different amounts of memory.
If a grades[5] array is stored at memory address 1000 onwards, then:
- grades[0] is at 1000
- grades[1] is at 1004
- grades[2] is at 1008
- grades[3] is at 10016
Each value is 4 bytes as we are storing an int which is 4 bytes long in a 32 bit system.
We can use this to develop assembly code that accesses arrays.
Example
/* Sum the elements of an array. */
...
int my array[5]; // declaration of an array of integers
myarray[0] = 1; // initialise the array
myarray[1] = 3;
myarray[2] = 5;
myarray[3] = 7;
myarray[4] = 9;
_asm {
...
lea ebx, myarray // addr of array (0th element) in ebx
mov ecx, 5 // size of the array in ecx (for Loop1)
mov eax, 0 // initialise sum to 0
Loop1: add eax, [ebx] // get element pointed to by ebx
add ebx, 4 // to pint to next integer element
loop Loop1 // go round again
...
}
...
A subroutine is a section of code which can be invoked repeatedly as the program executes.
Reason for Use
- Save effort in programming.
- Reduce the size of programs.
- Share code.
- Encapsulate or package a specific activity.
- Provide easy access to tried and tested code.
Subroutines in Assembly
Before we answer the above questions, let us look at how subroutines can be declared ans used in assembly language.
The declaration of a simple procedure looks as follows:
label PROC
...
RET ;return
label ENDP
The subroutine is initiated by writing CALL label.
PROC and ENDP are not part of the Intel x86 instruction set. We must call a C library functions from the inline assembler.
The CALL Instruction
CALL does the following:
- Records the current value of the IP as the return address.
- Puts the required subroutine address into the IP, so the next instruction to be executed is the first instruction of the subroutine.
The RET Instruction
RET retrieves the stored return address and puts it back into the IP, causing execution to return to the instruction after the CALL.
Nested Calls
The deeper the nesting of subroutines calls, the more space we need to store all return addresses.
Ideally, we’d like to stack return addresses as calls are made, and unstack them in reverse order on return:
graph LR
A -->|1| B
B -->|2| C
B -->|4| A
C -->|3| B
Using a Stack
CALL does the following:
- Records the current value of the IP as the return address; puts it on top of the stack.
- Puts the required subroutine address into the IP, so the next instruction to be executed is the first instruction of the subroutine.
RET does the following:
- Takes the address on top of the stack and puts it into the IP.
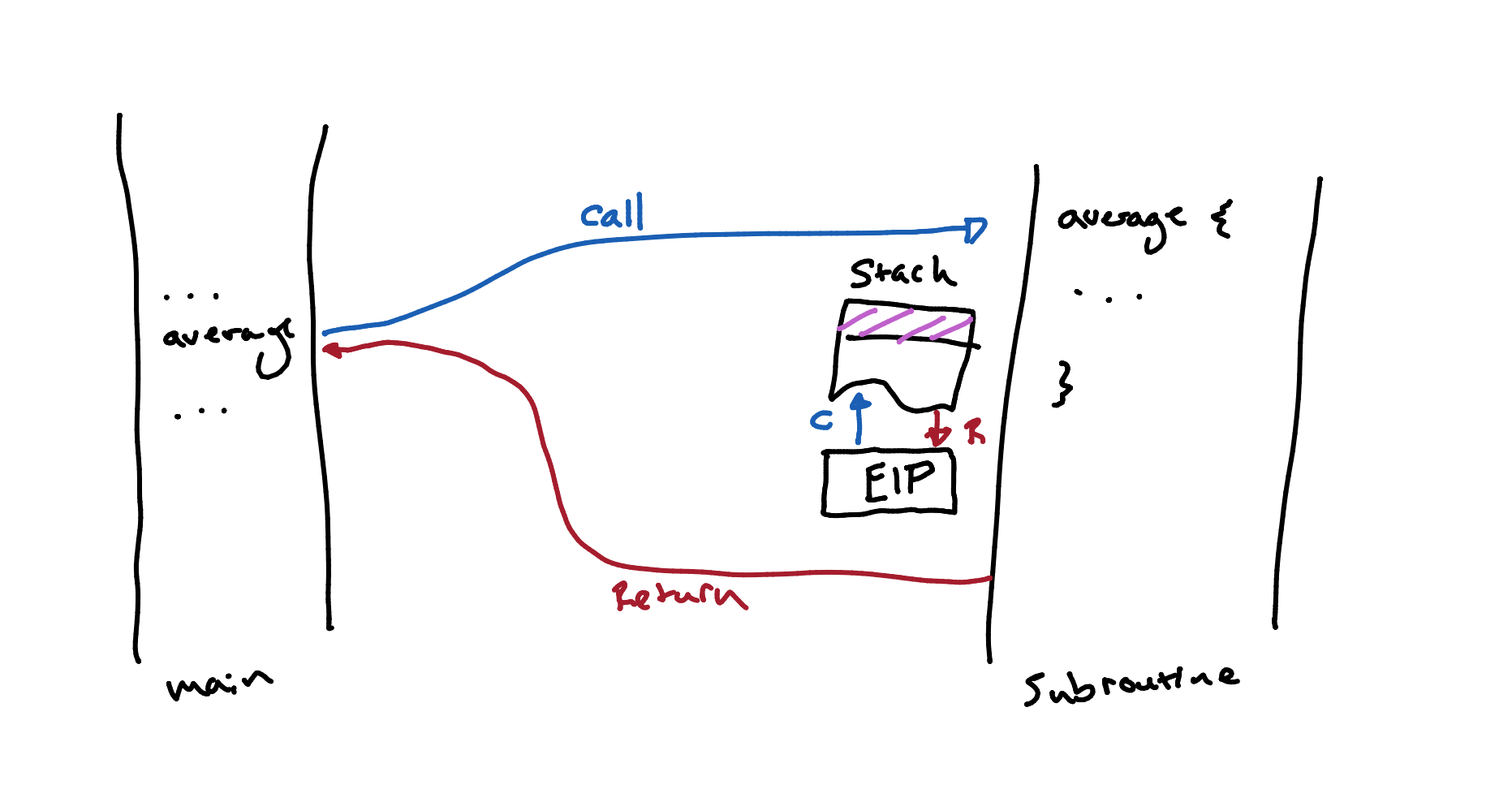
A stack is a memory arrangement for storing and retrieving information. The order of storing an retrieving values from the stack can be described as LIFO (last in first out).
The alternative would be a queue which is FIFO.
Operations
The operations on stacks are push and pop.
- Pushing
a will push the contents of a to the stack.
- Popping
a will pop the top data from the stack and load it into a.
Machine Level Stacks
PUSH and POP instructions make used of the stack pointer register ESP. This holds the address of the item which is currently on top of the stack.
In x86 architecture the stack goes down in memory.
PUSH and POP
The push instruction:
- Decrements the address in ESP so that it points to a free space on the stack.
- Writes an item to the memory location pointed to by the ESP.
The POP instruction:
- Fetches the item addressed by the ESP.
- Increments the ESP by the correct amount to remove the item from the stack.
It is the programmers responsibility to ensure that items are not left on the stack when no longer needed.
The Stack in Memory
The stack grows downwards in memory and the program is stored upwards in memory.
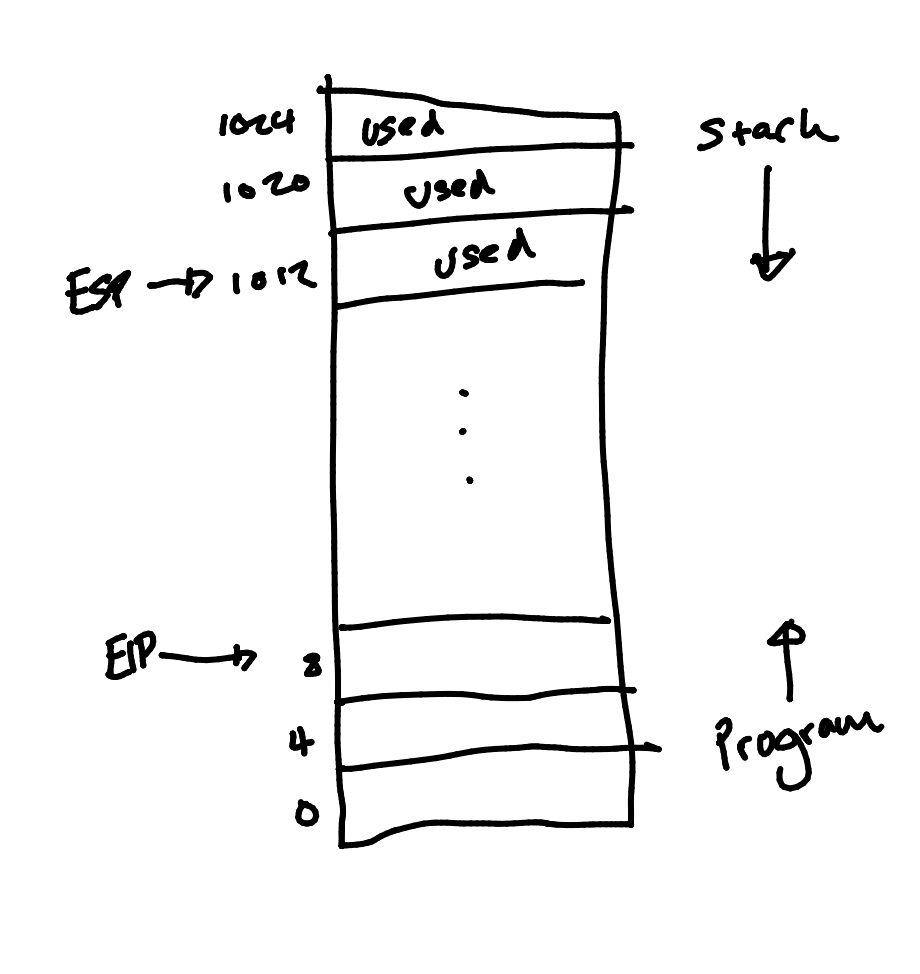
In this diagram:
- ESP - Stack pointer
- EIP - Instruction pointer
The locations increase by 4-bytes each time due to the 32-bit word length.
Adjusting the Stack
Items can also be removed from the stack, or space reserved on top of the stack, by directly altering the stack pointer:
add esp, 8 ; take 8 bytes off the stack
sub esp, 256 ; create 256 bytes of space on stack
The simplest kind of subroutine performs an identical function each time it is called and required no further information.
There are two main forms of parameters:
- Value parameters
- Reference parameters
Value Parameters
In this case the additional information will be some static value. If your function uses a value then you are passing by value.
Reference Parameters
These are the addresses of variables and not the values themselves. This would be useful if the subroutine changes the memory contents in-place, as opposed to returning a value.
This is known as pass by reference.
Using Registers for parameters
This is the simplest method of passing parameters into subroutines.
Both types of parameter can be passed this way.
Example - Pass by Value
Call procedure to determine bigger of 2 numbers. The numbers are passed in eax and ebx. Result returned in eax.
...
mov eax, first
mov ebx, second ; calling
call bigger ; sequence
mov max, eax
...
bigger: proc
cmp eax, ebx
jl second_big
ret
second_big:
mov eax, ebx
ret
bigger: endp
Example - Pass by Reference
Swap 2 variables by passing their addresses in eax and ebx.
...
lea eax, first
lea ebx, second
call swap
...
swap: proc
mov temp, [eax]
mov [eax], [ebx]
mov [ebx], temp
ret
swap: endp
Problem
If you have more than three parameters is is better to use the stack to avoid running out of registers.
Example
Call a procedure to multiple top 2 values on stack, leaving result in eax.
push num1 ; put first num on stack
push num2 ; put second num on stack
call multiply
mov result, eax ; store result
...
multiply: proc
pop ebx ; save return address
pop eax ; pop a value from stack to eax
mov tmp, eax ; store this value
pop eax ; pop next value from the stack
mul eax, tmp ; multiply the two values
push ebx ; put ret address back on stack
ret
multiply: endp
We must save the return address from the top of the stack when we use the stack for procedures.
This calls the subroutines from the C libraries to provide I/O functions.
External Subroutines
In order to call external subroutines from assembly the parameters need to be pushed to the stack.
printf
This function prints to the standards output.
- It expects its parameters to be on the stack.
- It expect the string parameter to be passed by reference.
- It will not remove the parameter from the stack, so you must do it afterwards.
Assembly Example
#include <stdio.h>
#include <stdlib.h>
int main (void) {
char msg[] = "Hello World\n"; // declare string in c
_asm {
lea eax, msg ; put address of string in eax
push eax ; stack the parameter
call printf ; use library function
pop eax ; take parameter off stack
}
return 0;
}
Looping Problem
Suppose we want to print our message 10 times. Then we might try making a standard loop.
The issue is that we don’t know what is going on inside the external routine. As a result we have to assume that any registers we are using will be overwritten.
This means we must save register values before the call, and restore them after. This should be done via the stack.
mov ecx, 10 ; set up loop counter
loop1:
push ecx ; save ecx on stack
lea eax, msg
push eax ; stack the parameter
call printf ; use the function
pop eax ; remove param
pop ecx ; restore ecx
loop loop1 ; loop based on ecx
The string parameter to printf() can contain format specifiers.
Each format specifier refers to another parameter, and tell printf() how it should be printed.
int age = 21; char name[] = "Bob";
printf("My name is %s and my age is %d\n", name, age);
This will print:
My name is Bob and my age is 21.
Some formats:
%d - Print as decimal integer.%s - Print as string.%c - Print as character.%f - Print as floating point.
Example
We will do the equivalent of:
printf("Number is %d\n", n);
We have to pass both paramters:
- The string’s address.
- The value of
n.
These must be paced on the stack in reverse order.
#include <stdio.h>
#include <stdlib.h>
int main (void) {
char msg[] = "Number is %d\n", n;
int n = 157;
_asm {
push n ; push the int first
lea eax, msg
push eax ; now stack the string
call printf
add esp, 8 ; clean 8 bytes from stack
}
return 0;
}
The final instruction cleans the data from the stack without loading each value into eax.
scanf
Reading values from the keyboard can be achieved by using scanf():
scanf("%d", &num); // format specifiers for inputs are mandatory
We have to tell scanf() where to put the item being read. That means passing the address of the variable.
Example
char fmt[] = "%d";
int num;
_asm {
lea eax, num ; we need to push the address of num
push eax
lea eax, fmt ; now the format string
push eax
call scanf ; on return the value will be stored
add esp, 8 ; clean stack
}
Local Variables
Consider a subroutines that contains variable declarations:
int sub1 (int n) {
int x; float y; char z;
...
}
The variables x, y, and z are local variables
:
- They only exist while the subroutine is active.
- Then the subroutines exist, the local variables disappear.
Stack Frames
The a HLL subroutines is called, a new stack frame is created on the stack (by the compiler).
The stack frame holds data pertinent to this particular call, including:
- Return address
- Parameters
- Local Variables
ESP and EBP
Because of nested calls, several stack frames may be present simultaneously.
The ESP always points to the top of the stack; however, this may alter as space is created for local data.
Another register, the EBP (base pointer), remains stable and can be used to a access parameters and variables:
- Add or subtract offset to EBP.
Stack Frames
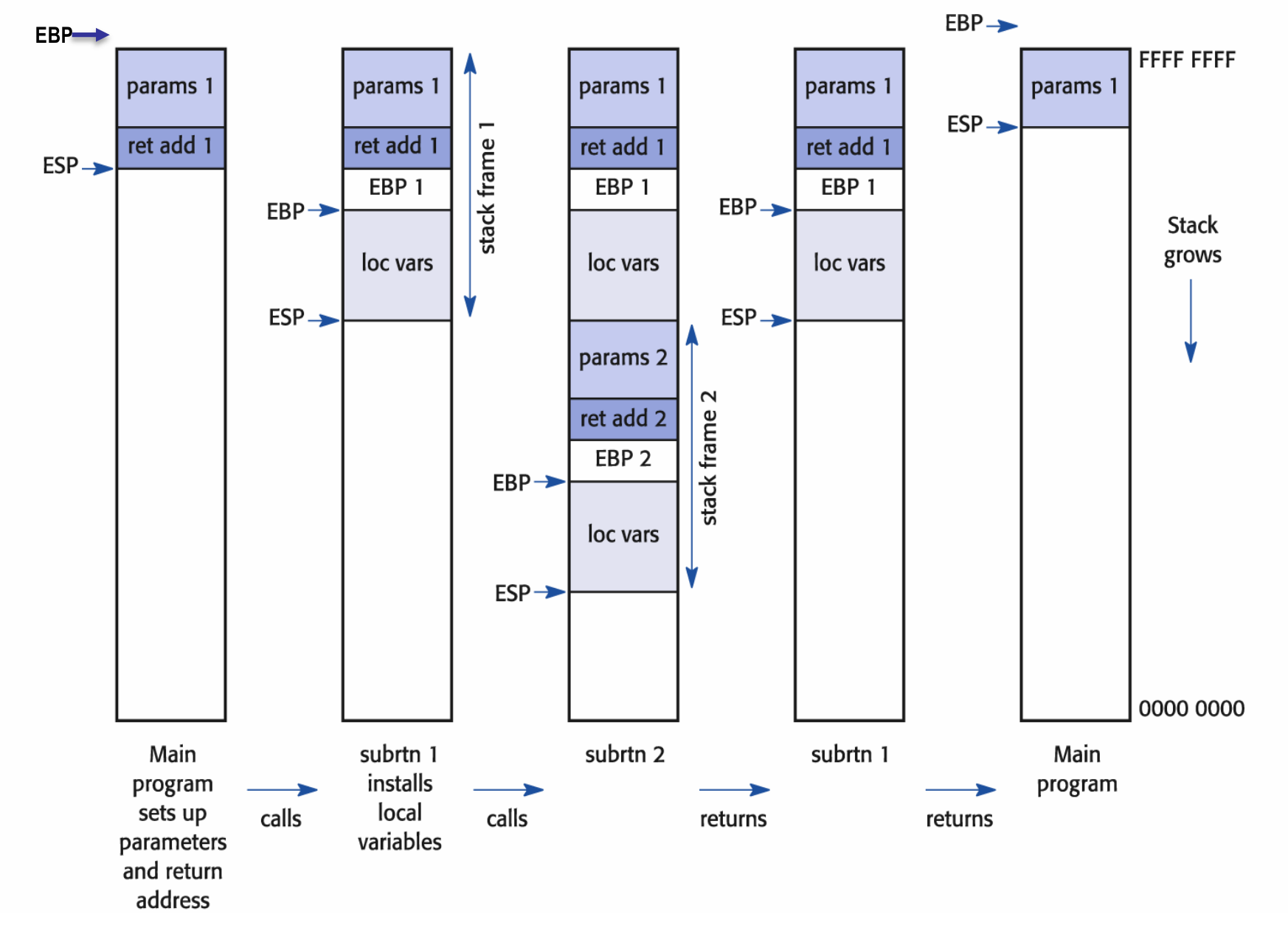
The stack frame is made of the following components:
- Parameters
- Return addresses
- The previous base pointer location
- Local variables
How Does it Work?
- ESP is always pointing to the top of the stack.
- EBP initially contains address of base of the stack.
When calling a subroutine to following happens:
- The parameters are pushed onto the stack.
- The return address is pushed onto the stack.
- The old EBP is pushed onto the stack.
- The current address of the top of the stack is put onto EBP.
- The local variables are installed on the stack, causing the ESP to alter.
When call returns:
- Clean up local variables.
- Restore previous stack base by popping into EBP.
- Pop return address into IP.
Calling routine is responsible for cleaning it’s parameters from the stack.
A recursive subroutine is one that may call itself to perform some subsidiary task.
If a subroutine is calling itself then it makes a new stack frame for each recursion.
Recursion may also appear in the form of mutual recursion.
Factorial Example
factorial(1) = 1
factorial(n) = n * factorial(n - 1)
In order to make a recursive function, you need a base case(to terminate execution) and some method to progress to the base case.
Implementation in Java
...
static int f(int n) {
if (n < 2) return 1;
return n * f(n - 1);
}
...
As an alternate to pattern matching we are using a if statement to make the decision.
Implementation in Assembly
This will multiply the top 2 items on the stack and leave the result in EAX:
multiply PROC
pop ebx
pop eax
mov tmp, eax
pop eax
mul eax, tmp
push ebx
ret
multiply ENDP
factorial PROC ; parameter n is passed via eax
cmp eax, 2 ; check if n < 2
jl rtn1
push eax ; push current value of n
dex eax ; decrease the value of n
call factorial ; recursively call factorial
push eax ; push the result
call multiply ; n * fac(n - 1)
ret ; return with result in eax
rtn1:
mov eax, 1 ; zero or one factorial is 1
ret ; return with result in eax
factorial ENDP
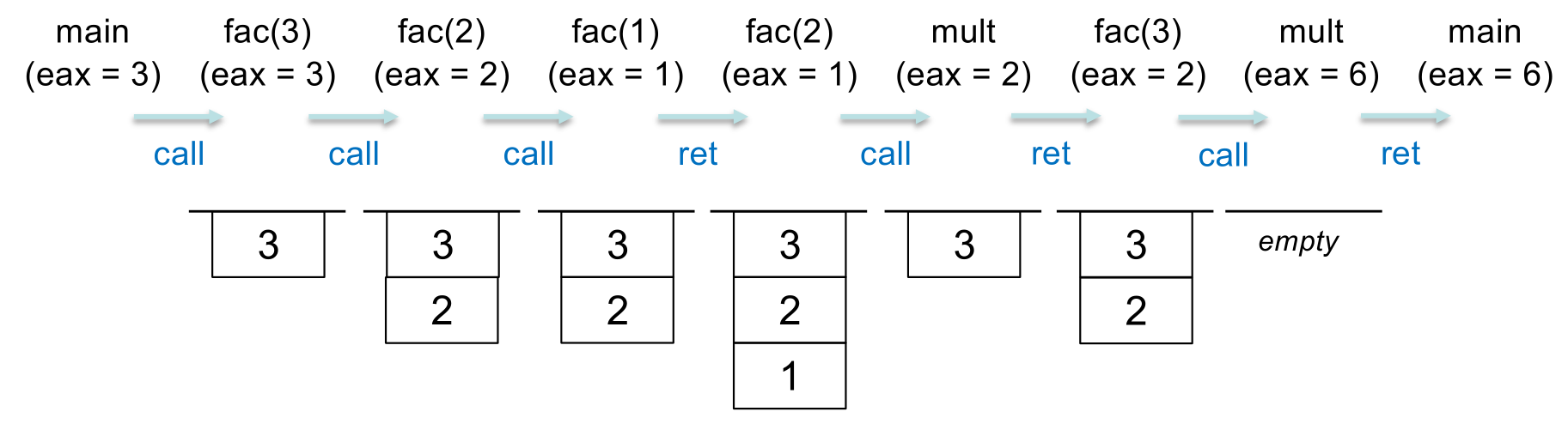
Consider computing the factorial of 3. Calling the sequence might be:
mov eax, 3
call factorial
// now eax contains result
This shows the parameters that are on the stack at each call:
Largely driven by desire to do something useful when a program cannot continue. We want the CPU to be busy all the time.
Early Systems
- Job loaded from punched cards or tape, output to printer.
- Job may include loading compiler, assembler, linker, data.
- CPU idle for much of the time.
- Jobs run sequentially, from start to finish.
Batch Systems
- Job passed to human operator.
- Operator groups jobs into batches with similar characteristics, e.g. all programs using same compiler.
- More efficient use of resources (still lots of wasted time waiting for a person).
Multiprogramming
- Load several programs into memory simultaneously, all sharing single CPU.
- When running program cannot continue (e.g. waiting for I/O), switch to another.
- Hence, I/O and computation overlap.
Sharing the CPU
graph RL
subgraph Program 1
13 --- 14[executing]
12 --- 13[I/O]
11[executing] --- 12[waiting]
end
subgraph Program 2
21[executing] --- 22[I/O]
22 --- 23[waiting]
end
subgraph Program 3
31[executing] --- 32[I/O]
end
Problems encountered with compute-bound programs and I/O-bound programs.
Multi-Access (Time-Sharing)
An extension of multiprogramming.
CPU is switched rapidly between processes to give illusion of uninterrupted execution in parallel (multitasking).
- Users can interact with programs.
- Users see their own ‘virtual machine’.
- Resources (printers, disks etc.) are shared, but this is largely transparent.
Time-sharing the CPU
graph RL
subgraph Program 1
11[executing]---12[waiting]---13[executing]
end
subgraph Program 2
21[waiting]---22[executing]
end
subgraph OS Dispatcher
31[waiting]---|clock Interrupt|32[waiting]---|clock Interrupt|34[waiting]
end
Each running program is allocated a fixed time
slice (quantum).
The time-sharing mechanism depends crucially on the ability to interrupt execution at regular clock intervals.
There are many circumstances in which it is desirable to interrupt the normal flow of a program to react to special events:
- User interrupt from the keyboard.
- Attempt to execute an illegal instruction.
- Completion of an I/O task.
- Power on or off.
Interrupts
An interrupt is a form of automatic call of a sequence of instructions, brought about (usually) by an event occurring outside normal program execution.
Such a sequence of instructions is known as an interrupt service routine (ISR). Variants are:
- Interrupt routine
- Interrupt handler
Unlike an ordinary subroutine call, an interrupt can take place at any point in the execution sequence.
The address of each ISR is usually contained in
an interrupt vector.
Servicing Interrupts
Certain interrupts (e.g. clock timeout) will not return control to the interrupted program. Instead, control is handed to another program (context switch).
If the programmer does not know when this will
happen, how do we protect the register values of the
original program?
- Answer is for OS to save them all in a special data structure called the process control block (PCB).
- The OS maintains a table of such descriptors, one for each process.
- Register values can be reloaded when execution resumes at a later time.
Processes
A program is a representation of an algorithm in some programming language; i.e. it is static.
- Source program (Java, assembly language, etc.)
- Object program (binary machine code)
A process refers to the activity performed by a computer when executing a program; i.e. it is dynamic.
A process is created when a program or command
is executed. However, the correspondence is not always one to one:
- A single program may give rise to several processes.
- Many programs may be executed within a single
process.
OS Structure
Often consists of:
- A central kernel:
- Resides permanently in memory.
- Performs low-level, frequently needed activity.
- A set of processes:
- May be created by kernel or to service user activity.
Processes interact with kernel via system calls:
- Create process
- Run program
- Open file
The kernel (and some system processes) may operate in privileged mode (also called kernel mode or special state)
System Initialisation
- On power-up or reset, an interrupt causes computer to execute bootstrap program held in ROM.
- This code initialises system, runs diagnostic checks, sets up basic I/O.
- It loads OS kernel from boot partition of specified external disk drive, and passes control to it.
- Kernel performs further initialisation and creates various system processes.
- Further processes may be created because of
user activity.
Command Interpreter
Often referred to as a shell. Accepts and runs commands specified by user and provides the user’s view of OS:
- May be graphical:
- May be textual:
Some commands built into shell, others loaded from separate executable files. Shell also has sophisticated control structures such as loops, if-statements and procedures.
The shell is just a normal user-level process.
System Calls
User processes are not allowed to inspect or alter kernel code, or to make calls directly to its subroutines.
System calls allow programs to request the kernel’s services:
- Often implemented as software interrupt.
- Many system calls are given a ‘wrapper’ to make them look like ordinary subroutines.
- Together with other useful functions, they
form an Application Programmer Interface
(API)
Operating Systems
The purpose of operating systems is to:
- Turn base hardware into a usable machine.
- Make efficient use of available resources, particularly when they are shared.
Abstract of Components
flowchart TD
uci[User Command Interface] <--> mm[Memory Manager] & fm[File Manager] & dm[Device Manager] & pm[Processor Manager]
mm <--> fm & dm & pm
fm <--> dm
fm <--> pm
dm <--> pm
Everything can talk to every other thing.
All but the UCI are the four essential managers of every OS, each working with the others to perform its task:
- Memory Manager
- Processor Manager
- Device Manager
- File Manager
Network functions were not always an integral part of an OS.
- A Network Manager can be added to handle networking tasks.
- User Command Interface
- How users interact with the OS by issuing commands.
Manager Functions
Each subsystem manager must perform the following tasks:
- Continuous monitoring of resources.
- Enforcement of policies that determine who gets what resources, when they get them and how much.
- Allocation of resource when it is appropriate.
- De-allocation of resources when finished.
Memory Manager
This manager is in charge of main memory and making sure requests are legal.
Tasks
- Preserves and protects the space in main memory that is occupied by the OS itself.
- Checks validity of each request for memory space.
- For legal requests, allocates areas of memory not already in use.
- In a multi-user system, keeps track of which users are using which section of memory.
- De-allocates sections of memory that are no longer needed.
Processor Manager
The processor manager decides how to allocate the central processing unit (CPU).
Tasks
- Creates processes when necessary to carry out tasks.
- Performs initialisation of new processes.
- Keeps track of the status of processes.
- Assigns processes to the CPU when available.
- Changes process states as events occur.
- Handles termination of processes on completion or abort.
- Handles inter-process communication.
- Manages process queues and prioritisation.
Device Manager
The device manager monitors every device and control unit.
Tasks
- Allocates the system’s devices (printers, disk drives), in accordance with the system’s scheduling policy.
- Deals with multiple requests for same device.
- Performs communication with the device during operation.
- De-allocates devices when no longer required.
File Manager
The file manager keeps track of every file in the system.
Tasks
- Organises all files, including data files, compilers, application programs, into directory structures.
- Manages the locations of files on disk.
- Enforces restrictions on who has access to which files (using a pre-determined access policy).
- Deals with all standard file operations.
- Open, close, delete, read, write.
Network Manager
The Network Manager provides the facilities for users to share resources while controlling user access to them:
- Resources connected to local network.
- Disks, printers…
The network stack provides access to the network.
We will not be looking at networking on this module.
Interaction Between OS Managers
Each OS manager has specific, individual tasks to perform but, it is not enough for each to operate on its own.
Example
Suppose a user types in a command at the keyboard to execute a program. The following steps must occur in sequence:
- Device manager
- Receives keystrokes and builds up command line. Informs processor manager that input has been received.
- Processor Manager
- Activates process awaiting a command. Process checks validity of command, and then tries to execute the corresponding program.
- File Manager
- Checks to see if the program file is already in memory. If not, it finds it on external storage and issues request for it.
- Device Manager
- Communicates with the disk drive and retrieves the program file from disk.
- Memory Manager
- Allocates space for the program and records its location. Continues to deal with changes to memory requirements as program runs.
- Processor Manager
- Creates a process for the new program and begins its execution.
This lecture goes more in depth on the tasks of the process manager.
Processes
We have seen that a process is the basic unit of work in a computer system. The OS processor manager is responsible for every aspect of a process.
It must:
- Allocate initial memory for the process.
- Continue to ensure that memory is available to the process, as it is needed.
- Assign the necessary files and I/O devices.
- Provide stack memory.
- Schedule CPU execution time for the process.
- Restore the system facilities and resources when a process is completed.
Process Descriptors
For each process, the OS kernel maintains a descriptor or process control block (PCB)
PCB contains info like:
- Unique process ID
- User ID of process owner
- Process state
- Position in memory
- Accounting stats
- Resources allocated
- Open files, devices, etc.
- Register values
- Instruction pointer, etc.
Process states
A process goes through possibly many changes of state during its lifetime. The OS must keep track of these, and update the PCB accordingly.
A process could be in the following states:
- Running
- On a uni-processor machine, only one process can be executing at any time.
- May be interrupted at end of time-slice if no I/O requests or system calls performed.
- Ready
- Refers to a process that is able to run, but does not currently have the CPU.
- Waiting/Blocked
- Refers to a process that is unable to continue, even if granted the CPU.
State Changes
These states can be shown in the following loop:
graph TD
new -->|admitted| ready
blocked -->|IO event or completion| ready
running -->|IO or event wait| blocked
ready -->|dispatch| running
running -->|exit| terminated
On most systems, processes are created (spawned) by other processes. The original process is the parent, and the new process is the child.
Hence we end up with a kind of ancestral
tree of processes.
Unix
- The
exec() system call allows one program to execute another:
- They stay in same process.
- New program overwrites caller
- The
fork() call spawns a new process:
- Child is identical to parent.
- The
wait() call suspends parent until child terminates.
Execution Scenarios
-
P1 execs P2:
graph LR
P1 --> P2
P2--> 1[ ]
-
P1 forks, then child execs P2:
graph LR
P1 --> P2
P1 --> 1[ ]
P2 --> 2[ ]
-
The same as before by now P1 issues a wait() call.
graph LR
P1 --> P2
P1 -.-> 1[ ]
P2 --> 1[ ]
1 --> 2[ ]
Unix Processes
- At startup, kernel creates process 0:
- Kernel-level process, so can access kernel code and data structures directly.
- Eventually becomes swapper, responsible for moving processes to/from disk.
- Before this, it spawns other kernel-level processes.
- Process 1 is
init (now systemd on Linux):
- Parent of all other processes.
- Spawns daemon processes.
- Spawns process for user login.
- Unix processes:
- When user logs on, the login process checks name and password against stored details, then execs shell.
- User can alter their preferred choice of shell.
- Shell prompts for commands, then forks and execs to carry out those commands.
- At logout, shell process dies:
init/systemd is informed, and creates new login process.
Zombies and Orphans
Parent processes usually wait for their children to die. If the death of a child is not acknowledged by the parent (via wait call), the child becomes a zombie:
- No resources, but still present in process table.
If parent dies before its children, the children become orphans
- Get “adopted” by
init process.
Daemons
- Not associated with any user or terminal.
- Run permanently in background.
- Perform tasks requested of them by other processes.
- Carry out the background tasks of the OS:
- Subsystem managers are background processes.
- They need their own time on the CPU.
Process interaction
Processes that do not need to interact with any other processes are known as independent processes.
In modern systems, many processes will work together. These are known as cooperating processes.
The operating system provides synchronisation and communication mechanisms for cooperating processes.
Synchronisation & Communication
Synchronisation
If a process can only do its work when another process has reached a certain point, we need a way of informing it such as:
Unix Signals
A process can usually be terminated by typing CTRL-C:
- Actually sends a signal to process.
- Process responds by aborting.
Signals can be sent from one process to another:
Signals can be sent from the command line using kill command:
kill -9 12345 sends signal 9 (kill signal) to process 12345
Responding to Signals
A receiving process can respond to a signal in three ways:
- Perform default action (e.g. abort).
- Ignore the signal.
- Catch the signal:
- Execute a designated procedure.
The ‘kill’ signal (signal 9) cannot be caught or ignored.
- Guaranteed way to stop process
Example Kill Signals
| Number |
Name |
Action |
| 1 |
HUP |
Hang up |
| 2 |
INT |
Interrupt |
| 3 |
QUIT |
Quit |
| 6 |
ABRT |
Abort |
| 9 |
KILL |
Non-catch-able, non-ignorable kill |
| 14 |
ALRM |
Alarm clock |
| 15 |
TERM |
Software termination signal |
Pipes
The UNIX command wc –l <file> counts the number of lines in file.
If we just type wc –l we don’t get an error. Instead, data is read from standard input (keyboard by default).
- Similarly for output files and standard output (screen).
The pipe symbol | attaches the standard output of one program to the standard input of another:
Common wc flags
| Flag |
Action |
-l |
Number of lines |
-w |
Number of words |
-c |
Number of characters |
By default, all three stats are displayed. Flags state what stats appear.
Sockets
A socket is a communication endpoint of a channel between two processes:
- Unlike pipes, communication is bi-directional.
- Unlike pipes, the processes:
- Do not need to have the same lineage.
- Do not need to be on the same machine.
- Do not even need to be on the same local-area network.
When two processes communicate using sockets, one is designated the server and the other the client:
- In some cases, doesn’t matter which is which.
More usually, a daemon server process offers a service to many clients.
Usually pipes and sockets are implemented as files in a special part of the file system.
In any mutliprogramming situation, processes muyst be scheduled.
The scheduler selects the next job from the ready queue:
- Determines which process gets the CPU, when and for how long. Also when processing should be interrupted.
- Various algorithms can be used
Scheduling algorithms may be preemptive or non-preemptive
Non-Preemptive Scheduling
Once CPU has been allocated to a process the process keeps it until it is released upon termination of the process or by switching to the waiting state.
Preemptive Scheduling
Preemptive algorithms are able to stop what is currently running on the CPU to swap another process on.
Scheduling Policies
Several criteria could be considered:
- Maximise Throughput
- Complete as many processes as possible in a given amount of time.
- Minimise Response Time
- Minimise amount of time it takes from when a request was submitted until the first response is produced.
- Minimise Turnaround Time
- Move entire processes in and out of the system quickly.
- Minimise Waiting Time
- Minimise amount of time a process spends waiting in the ready queue.
- Maximise CPU Efficiency
- Keeps the CPU constantly busy by running CPU bound processes and not IO bound ones.
- Ensure Fairness
- Give every process an equal amount of CPU and IO time by not favouring only one regardless of its characteristics.
Often applying multiple of these will create conflictions.
Scheduling Algorithms
The scheduler relies an algorithms that are based on a specific policy to allocate the CPU.
First Come, First Served (FCFS)
- Uses a first-in-first-out (FIFO) queue.
- Non-preemptive algorithm that deals with jobs according to their arrival time.
- If the process is blocking then the process is returned to the back of the queue.
The process control block (PCB) of any new processes is linked to its place in the queue.
Example
Suppose we have three processes arriving in the following order:
- $P_1$ with CPU burst of 13 milliseconds.
- $P_2$ with CPU burst of 5 milliseconds.
- $P_3$ with CPU burst of 1 millisecond.
The burst time is the amount of time before the process blocks or terminates. You can have multiple bursts.
Using the FCFS algorithm we can view the result as a Gantt chart:
gantt
dateformat S
axisformat %S
P1: a, 0, 13s
P2: b, after a, 5s
P3: c, after b, 1s
From this we can calculate the average wait time as:
\[\frac{0+13+18}{3}=10.3\text{ms}\]
FCFS
Different Arrival Time
What if the order of arrival changed to the following:
gantt
dateformat S
axisformat %S
P2: a, 0, 5s
P3: b, after a, 1s
P1: c, after b, 13s
This would give the following average wait time:
\[\frac{0+5+6}{3}=3.7\text{ms}\]
This is significantly shorter than the original 10.3ms.
Advantages
Disadvantages
- The average wait time is generally not minimal and can vary substantially.
-
Unacceptable for use in time-sharing systems as each user requires a share of the CPU at regular intervals.
Processes cannot be allowed to keep the CPU for an extended length of time as this dramatically reduces system performance.
Shortest Job First
Example
Suppose we have the following four processes:
- $P_1$ with CPU burst of 5 milliseconds.
- $P_2$ with CPU burst of 9 milliseconds.
- $P_3$ with CPU burst of 6 millisecond.
- $P_4$ with CPU burst of 3 millisecond.
Using the SJF algorithm we can schedule the processes as viewed in the following Gantt chart:
gantt
dateformat S
axisformat %S
P4: a, 0, 3s
P1: b, after a, 5s
P3: c, after b, 6s
P2: d, after c, 9s
This gives the following wait times:
- 3 milliseconds for $P_1$.
- 14 milliseconds for $P_2$.
- 8 milliseconds for $P_3$.
- 0 milliseconds for $P_4$.
Thus, the average wait time is:
\[\frac{3+14+8+0}{4}=6.25\text{ms}\]
FCFS Comparison
If we had used FCFS the wait time would be:
\[\frac{0+5+14+20}{4}=9.75\text{ms}\]
We can see that this algorithm gives shorter wait times compared to FCFS.
Advantages
Disadvantages
- Can lead to starvation.
- May be difficult to estimate execution times.
- Often relies on previous history, which may not always be available.
Shortest Remaining Time First
- A preemptive version of the shortest job first algorithm.
- Based on the remaining time rather than the burst time.
- CPU is allocated to the job that is closest to being completed.
- Can be preempted if there is a newer job in the ready queue that has a shorter completion time.
Priority Scheduling
This is an algorithm that gives preferential treatment to important jobs.
- Each process is associated with a priority and the one with the highest priority is granted the CPU.
- Equal priority processes are scheduled in FCFS order.
- SJF is a special case of the general priority scheduling algorithm.
Priorities can be assigned to processes by a system administrator or determined by the processor manager on characteristics such as:
- Memory requirements.
- Peripheral devices required.
- Total CPU time.
- Amount of time already spent processing.
Example
Suppose we have five processes all arriving in the following order:
- $P_1$ with CPU burst of 9 milliseconds, priority 3.
- $P_2$ with CPU burst of 2 milliseconds, priority 2.
- $P_3$ with CPU burst of 1 milliseconds, priority 5.
- $P_4$ with CPU burst of 5 milliseconds, priority 3.
- $P_5$ with CPU burst of 6 milliseconds, priority 4.
Assuming that 0 represents the lowest priority, using the priority algorithm we can view the result as the following Gantt chart:
gantt
dateformat S
axisformat %S
P3: a, 0, 1s
P5: b, after a, 6s
P1: c, after b, 9s
P4: d, after c, 5s
P2: e, after d, 2s
This gives the following wait times:
- 7 milliseconds for $P_1$.
- 21 milliseconds for $P_2$.
- 0 milliseconds for $P_3$.
- 16 milliseconds for $P_4$.
- 1 milliseconds for $P_5$.
Thus, the average wait time is:
\[\frac{7+21+0+16+1}{5}=9\text{ms}\]
Advantages
- Simple algorithm.
- Important jobs are dealt with quickly.
- Can have a preemptive version.
Disadvantages:
Windows
Priorities are in a range of 0-31.
A new process is given one of 6 base priorities:
IDLE (4)BELOW_NORMAL (6)NORMAL (8) (Default)ABOVE_NORMAL (10)HIGH (13)REALTIME (24)
Normal processes can receive a priority boost when brought into the foreground.
A process can be boosted when it receives input or an event for which it is waiting.
For a boosted process, the priority is reduced by one level at the end of each time slice, until its base level is reached.
Preemptive algorithm that gives a set CPU time to all active processes.
- Similar to FCFS, but allows for preemption by switching between processes.
- Ready queue is treated as circular. The CPU allocates each process a time-slice.
Time Quantum - A small unit of time, varying anywhere between 10 and 100 milliseconds.
Ready Queue - Treated as a FIFO queue.
CPU scheduler selects the process at the font of the queue, sets the timer to the time quantum and grants the CPU to this process.
Edge Cases
- If the process’s CPU burst time is less than the specified time quantum, it will release the CPU upon completion.
- The scheduler will then proceed to the next process at the front of the ready queue.
- If the process’s CPU burst time is more than the specified time quantum, the timer will expire and execute an interrupt and execute a context switch.
- The interrupted process is added to the end of the ready queue.
- The scheduler will then proceed to the next process at the front to the ready queue.
Example
Suppose we have three processes all arriving at time 0 and having CPU burst times as follows:
- $P_1$ with CPU burst of 20 milliseconds.
- $P_2$ with CPU burst of 3 milliseconds.
- $P_3$ with CPU burst of 3 milliseconds.
Supposing a time quantum of 4 milliseconds, we can view the results as the following Gantt chart:
gantt
dateformat S
axisformat %S
P1: a, 0, 4s
P2: b, after a, 3s
P3: c, after b, 3s
P1: d, after c, 4s
P1: e, after d, 4s
P1: f, after e, 4s
P1: g, after f, 4s
Generally, you wouldn’t have one process taking many quantum due to the large number of processes.
Thus, the average wait time is:
\[\frac{(10-4)+4+7}{3}=5.66\text{ms}\]
The $10-4$ represents the 10ms wait time for $P_1$ take the time from it’s first run.
Advantages
- Easy to implement as it is not based on characteristics of processes.
- Commonly used in interactive/time-sharing systems due to its preemptive abilities.
- Allocates CPU fairly.
Disadvantages
Performance depends heavily on selection of a good time quantum:
- If time quantum is too large, RR reduces to the FCFS algorithm.
- If time quantum is too small, overhead increases due to the amount of context switching.
Real operating systems use a combinations of several scheduling algorithms. Windows uses priority round robin.
Disk Hardware
Disks are based around the concept of blocks:
- Disks are split into block of a certain size.
- Files fill up one or more blocks.
- Only one file can fill each block, so some wasted space if a file is smaller than the block.
Operating system determines the block size and imposes programmatic access to physical devices.
File System
- Logical vs. physical organisation of file.
-
Most file systems are tree-structured:
graph TD
/ --- etc
/ --- bin
/ --- usr
/ --- home
usr --- ub[bin]
home --- staff
home --- students
students --- folder1
students --- folder2
folder1 --- file1
folder1 --- file2
folder1 --- file3
The logical organisation is not related to the physical structure.
Directories
Non-leaf nodes are directories:
- Contain list of filenames plus further into about each file.
Unix Inodes
Directory entry consists of filename and inode number:
- Inode number references (points to) an inode file descriptor.
An inode contains info such as:
- File owner
- Permissions
- Modify and Access Times
- Size
- Type
- Regular
- Special (such as
/dev and links)
- Location on Disk
File Types
Windows uses file extensions to indicate application.
On Unix you can execute any file:
File-store Allocation
File-store is divided into fixed-size blocks.
Blocks not currently allocated to files are maintained in a free list.
Several strategies for allocating blocks:
- Contiguous
- Linked
- File allocation table (FAT)
- Indexed (NTFS)
The Free List
This represents the free block on a block device.
It can be a simple bit vector. Bit vectors are simple and efficient if kept in memory. There can be issues though:
- Needs writing to the disk every so often.
- May be huge:
- 80GB disk with 512 byte blocks needs 20MB for a free list.
An alternative is to chain all free blocks into a linked list.
These methods use the disk to store information about the allocation of the disk.
Contiguous Allocation
Each file is allocated a contiguous set of blocks.
graph TD
subgraph Filestore
eeny
meeny
miny
mo
end
Location of information consists simply of:
- Start Block
- Number of blocks.
Advantages
- Fast for both sequential and direct access.
Problems
- Fragmentation
- May need regular compaction.
- Number of blocks to allocate.
- File growth.
Linked Allocation
Each block contains a pointer to the next.
graph LR
subgraph Filestore
eeny1 --> eeny2
eeny2 --> eeny3
miny1 --> miny2
end
These blocks could be anywhere on the disk.
Could be improved by allocating blocks in clusters but this worsens internal fragmentation.
Advantages
- Easy to grow/shrink files.
- No Fragmentation.
Problems
- Blocks are widely dispersed.
- Sequential access less efficient.
- Direct access even worse.
- Requires $n$ reads to get to block $n$ (following the chain.
- Danger of pointer corruption.
File Allocation Table
Block allocations are held in a table located at the start of the partition.
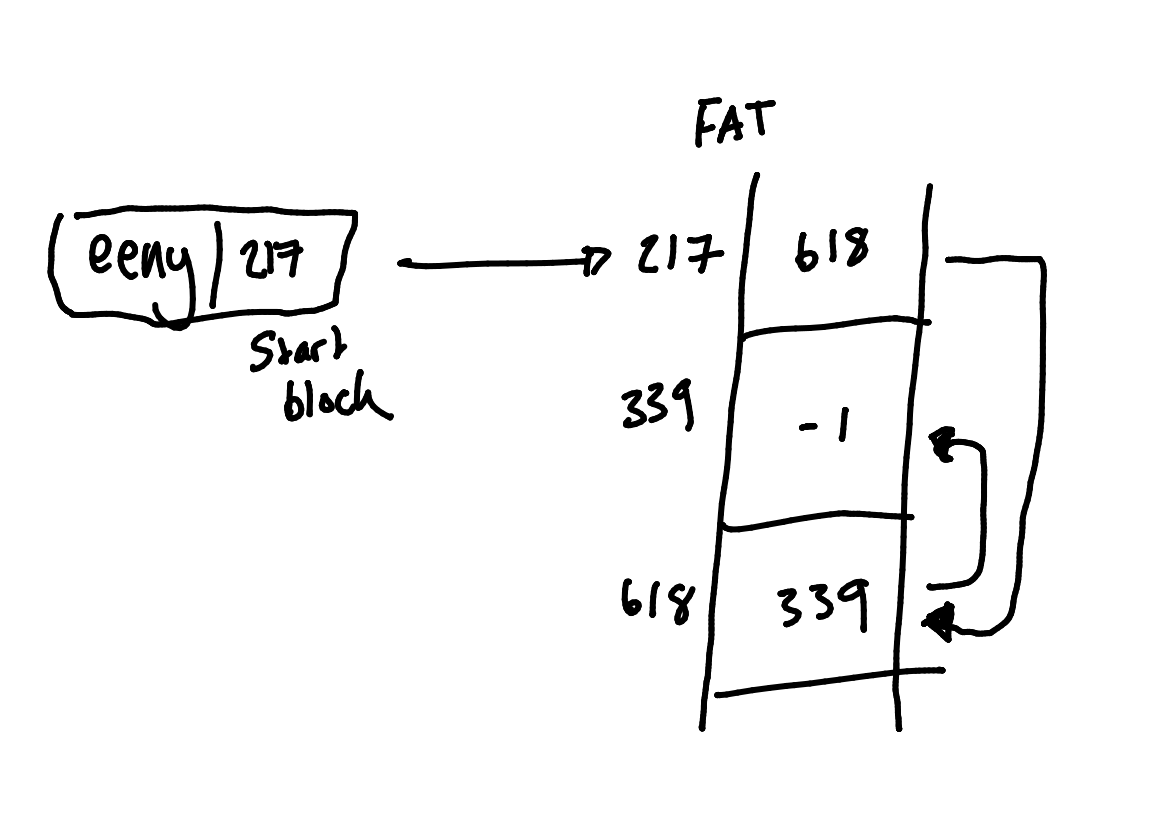
-1 is the end of the list of blocks.
0 indicates an unused block.
Advantages
- All pointer info held in one place (separate from the data).
- Easier to protect.
- No need for separate free list.
- Direct access much more efficient.
Problems
- May require drive head to shift constantly between the FAT and file blocks.
- FAT may become huge for large disks.
Indexed Allocation
First block holds index to all other blocks in the file.
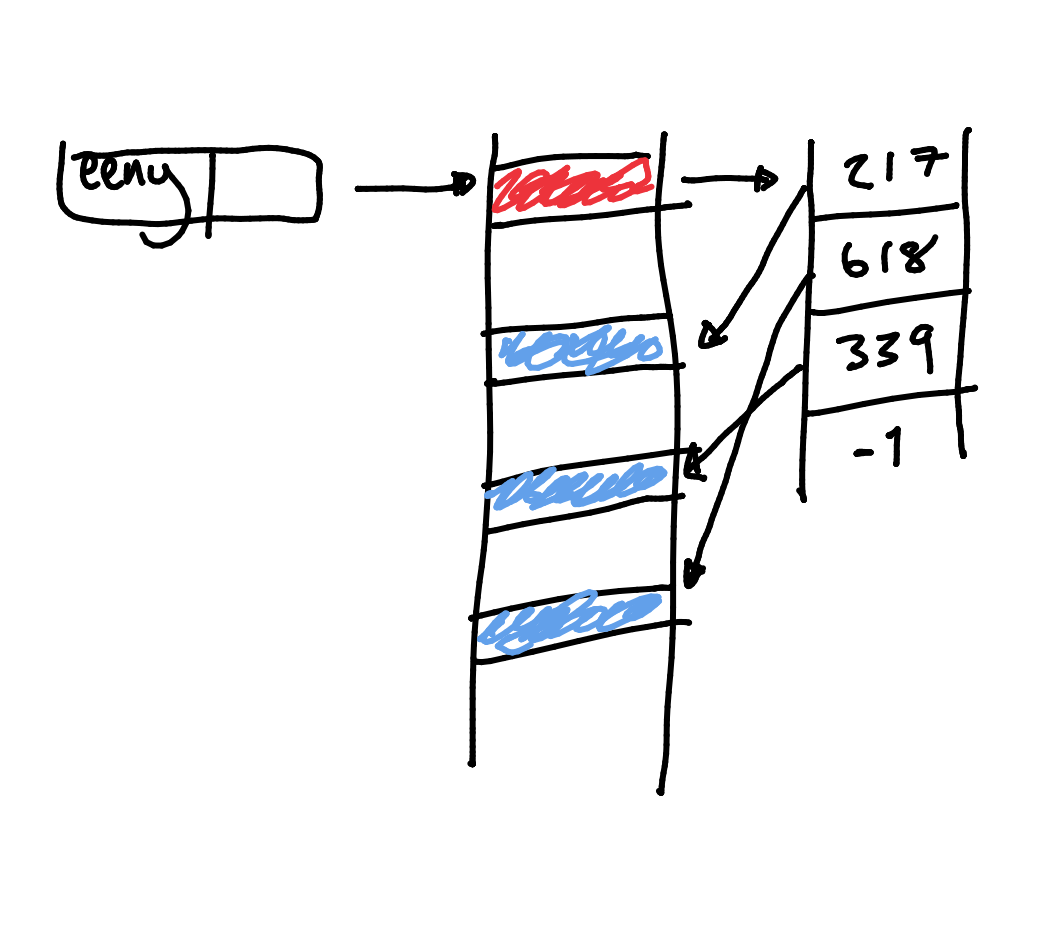
The inode is what points to the first block in a file.
Advantages
- Each file’s pointer info is held in one place.
- Very efficient for both sequential and direct access.
Problems
- Blocks may still be widely dispersed.
- Can tun out of pointers for large files.
- May have to chain several index blocks together.
Example - NTFS
- Has a master file table (MFT) using a form of indexed allocation.
- Files under 1 block will be contained entirely within the MFT to save space.
Devices
Peripheral devices connect to ports on the computer.
Data and commands to/from the devices may travel along a shared set of wires called a bus:
flowchart TB
CPU <--> Bus
1[Device] <--> Bus
2[Device] <--> Bus
3[Device] <--> Bus
- Devices ignore messages not intended for them.
- Problem of bus contention.
Communication
Devices usually have several registers:
- Status register
- Command/Control register
- To pass commands to device.
- Data register
CPU may have special I/O instructions to alter/inspect device registers:
- Very specialised applications.
Often registers are mapped onto memory locations:
- Writing to location
100 might send a command to a device.
- Makes I/O easier because we treat it just the same as writing to memory.
- Need to protect these memory locations from malicious use or corruption.
I/O Handling
flowchart TB
subgraph Software
Application <--> Kernel
subgraph Kernel
dd[Device Driver]
end
end
subgraph Hardware
dd <--> dc[Device Controller]
dc <--> Device
end
- The kernel talks to the device driver as a result of system calls.
- The device driver translates high-level abstract system calls into signals that can be recognised by the device.
Application I/O Interface
I/O devices can be categorised by their behaviours into generic classes:
- Each general type is accessed through an interface, which is a standard set of functions (though system calls may vary between OSs).
Device driver layer hides differences among I/O controllers from the kernel.
Devices vary on many dimensions:
- Character-stream vs. block.
- Sequential vs. random access.
- Sharable vs. dedicated.
- Multiple vs. single process.
- Speed of operation.
- Read-write, read only, or write only.
Device Handling
Device driver converts system calls to low-level commands to control the device.
- It may have to be installed for a new device.
- Treated as privileged code by the OS for kernel integration.
- Poorly written drivers may lead to system instability or security issues.
Device controller converts commands to electronic signals operating the hardware.
Application interface:
- At the application level, we want to treat devices as if they were files/streams.
- Accessing a special file activates the device driver.
- System call
ioctl() can be used to pass arbitrary commands to the device driver.
Example - Unix Terminal
flowchart LR
Process <-->|read/write| OS
subgraph OS
t[Terminal Device Driver]
end
t --> oq[Output Queue]
oq --> Terminal
Terminal --> iq
iq[Input Queue] --> t
- Characters typed at keyboard are entered into input queue by device driver.
- To echo, driver copies input queue to output queue.
- Some characters require further processing by device driver:
- Backspace removes an item from the input queue.
- When read request is made, pass contents of input queue to process.
I/O requests need to be scheduled to execute in an efficient order.
A good ordering can improve system performance, ensure devices are shared fairly amongst processes and reduce average I/O completion wait time.
Scheduling done via wait queues for each device:
- I/O scheduler may rearrange the order of the queue to improve efficiency and response.
- Priority may be given to requests requiring a fast response.
- Choice of different scheduling algorithms available for disk I/O:
- FCFS
- Shortest Seek Time First (SSFT)
Buffering
Consider reading a sequence of characters from a device. Making a read request for each character is costly.
Instead, set up an area of memory called a buffer:
- Read a block of chars into buffer in one operation.
- Subsequent chars are taken directly from the buffer.
- Only need to access device when buffer empties.
Similarly for writing:
- Place each char in a buffer.
- Send to device only when buffer is full.
Buffer writes can cause inconsistency problems:
- May need to flush buffers periodically (Unix sync operation every 30 seconds).
Buffering Techniques
- Double Buffering
- Read/write one buffer while other being filler/emptied.
- Done by graphics cards to avoid flicker.
- Buffering may be done by:
- Software
- Operating system or library routines.
- Hardware
- Direct Memory Access (DMA)
- Fast devices may write directly into a memory buffer, interrupting CPU only when finished.
- CPU might be delayed while DMA controller accesses memory (cycle stealing).
Caching
There is cache memory within the CPU. More generally, caching uses a faster medium to act in place of a slower one.
Areas of main memory can be used to cache copies of items on disk:
- May also lead to inconsistency problems.
Buffering vs. Caching
Buffering is about making data transit more efficient whereas caching is making repeated use or short bursts more efficient.
| Buffer |
Cache |
| Items viewed as data in transit. |
Items viewed as copies of original. |
| FIFO |
Random access. |
| Once item read, viewed as deleted. |
Items may be read many times. |
Spooling
Some devices are non-sharable:
- Multiple processes cannot write to it simultaneously, like a printer.
The solution is a daemon called a spooler.
SPOOL - Simultaneous peripheral operations online.
Method
- Processes send their printer output via the spooler daemon.
- Spooler creates a temp file for each process, and writes output to those files.
- When process completes, spooler adds file to a queue for printing (de-spooling).
A thread is an independent and parallel part of a process.
Each thread has its own:
- Program counter
- Stack space
However, unlike a process, threads share:
- Program code
- Data
- Open files and other system resources
with the other member threads in the process.
Threads are handled at a higher level than processes, and can be switched without involvement of the operating system kernel.
- If this is the case, thread switching is very rapid and efficient. such threads are known as user-level threads.
Threads are especially important for the development of event-driven programs.
Topology
A thread can be through of as a lightweight process.
Threads are created within a normal process.
Independent tasks can be split from the main process into individual threads.
Benefits
- Ease of Programming (modularity)
- Many applications need to perform several distinct tasks simultaneously. Much easier to create one separate thread per task, than to attempt to do them all within one linear program.
- Responsiveness
- In a multi-threaded interactive application a program may be able to continue executing, even if part of it is blocked.
- In a web browser: user waiting for image to download, but can still interact with another part of the page.
- Resource Sharing
- Threads share memory and resources of the process they belong to, thus we have several threads all within the same address space.
- Economy
- Threads are more economical to create and context switch as
they share the resources of the processes to which they belong.
- Utilisation of Parallel Architectures
- In a multiprocessor architecture, where each thread may be running in parallel on a different processor, the benefits of multi-threading can be increased.
Mathematical Example
Consider finding a single root using the quadratic formula:
\[x=\frac{-b+\sqrt{b^2-4ac}}{2a}\]
This can be split into several operations.
Concurrent Operations
These operations don’t rely on any other part of the expression.
- $t_1=-b$
- $t_2=b\times b$
- $t_3=4\times a$
- $t_4=2\times a$
Serial Operations
These parts have prerequisites.
- $t_5=t_3\times c$
- $t_5=t_2-t_5$
- $t_5=\sqrt{t_5}$
- $t_5=t_1+t_5$
- $x=\frac{t_5}{t_4}$
Java Threads
When a Java program starts up, a single thread is always created for the program
JVM also has own threads for garbage collection, screen updates, event handling…
- New threads may be created by the programmer by extending the Thread class.
- Threads may be managed directly by kernel, or implemented at user level by a library.
- Former is less efficient.
- In latter, if one thread blocks, all threads will block.
Java Thread Class
public class Thread extends Object implements Runnable
- A
Thread implements a run() method that defines what processing will be carried out during the Thread’s lifetime.
- Threads may be started within
main() and run simultaneously, sharing variables, etc.
Example
class Worker1 extends Thread {
public void run() {
System.out.println(“I am a worker thread”);
}
}
public class First {
public static void main (String args[]) {
Worker1 runner = new Worker1();
runner.start();
System.out.println(“I am the main thread”);
}
}
This doesn’t have a definite order. Worker1 or main may get run first.
Method
The class Worker1 is derived from the Thread class and the work of the new thread is specified in the run() method.
- In
main() we create a new Worker1 object.
- Calling the
start() method:
- Allocates memory and initialises the new thread.
- Causes the
run() method to be called.
- Original thread and new thread now run in parallel.
Java Thread States
graph LR
a[ ] -->|new| New
New -->|"start()"| Runnable
Runnable -->|"I/O, sleep()..."| Blocked
Blocked --> Runnable
Runnable -->|termination| Dead
All threads capable of execution are in the runnable state.
This includes the currently executing thread.
Problem
Suppose we have an object called Thing which has the following method:
public void inc() {
count++;
}
Indeterminacy
Assume the inc() method does these three things within the processor:
- Loads the value of count into a register.
- Increments the value of the register back into
count.
- Stores the value of the register back into
count.
The two threads could run and work perfectly most of the time, but sometimes the order of parallel operations might case a problem:
| $T_1$ |
$T_2$ |
count |
LOAD(0) |
|
0 |
ADD(1) |
|
0 |
| |
LOAD(0) |
0 |
| |
ADD(1) |
0 |
| |
STORE(1) |
1 |
STORE(1) |
|
1 |
This is called a race condition.
This is very hard to debug as the program will mostly work correctly as the issue is in-determinant.
Mutual Exclusion
Indeterminacy arises because of possible simultaneous access to a shared resource.
The variable count in the example.
The solution is to allow only one thread to access count at any one time; all others must be excluded.
When a thread/process accesses any shared resource, it is in a critical section (region).
One way to enforce mutual exclusion is via semaphores.
Semaphores are a token that you must acquire before entering a critical region.
This could be a shared resource.
Usage
A semaphore is a variable that is used as a flag to indicate when a resource is free or in use:
0 means a resource is in use.1 means that the resource is free.
Semaphore can only be changed by two operations:
wait and signal.- Sometimes called:
P and Vtest and incup and down
When a process issues a wait on the semaphore:
- If it is
0, add process to the semaphore queue and suspend (block) process.
- If it is
1, process continues execution.
When a process issues a signal on the semaphore:
- Set semaphore to
1.
- Take any waiting process from the queue and resume its execution.
The wait operation blocks until the resource becomes available.
Increasing, decreasing and testing the semaphore must be atomic operations to avoid race conditions between processes and the semaphore variable.
wait() & signal()
These functions are indivisible (atomic) operations:
When one thread is executing the code between them, no other thread can do so.
They can be used to enforce mutual exclusion by enclosing critical regions.
Java provides a semaphore class with acquire and release methods instead of wait and signal.
Types of Semaphore
- A binary semaphore can only take values of 0 or 1.
- Counting semaphores are unrestricted and allow control access to limited resources.
- When a process/task/thread is in a critical region (controlled by $S$), no other process (needing $S$) can enter theirs.
- Hence, keep critical regions as small as possible.
Use of semaphores requires careful programming.
A producer process and a consumer process communicate via a buffer.
- Producer Cycle:
- Produce item.
- Deposit in buffer.
- Consumer Cycle:
- Extract item from buffer.
- Process the item.
There can be many producers and consumers, sometimes in a chain.
Issues
We have to ensure that:
- Producer cannot put items in a full buffer.
- Consumer cannot extract items from buffer if it is empty.
- Buffer is not accessed by two thread simultaneously.
Implementation
Main Thread
public class Prodcon
{
public static void main (String args[])
{ // Create buffer, producer & consumer
Buffer b = new Buffer();
Producer p = new Producer(b);
Consumer c = new Consumer(b);
p.start(); c.start();
...
}
}
Producer and Consumer Classes
class Producer extends Thread {
private Buffer b;
public Producer (Buffer buf) {
b = buf;
}
public void run() {
int m;
...
b.insert(m);
...
}
}
Consumer is similar, but calls n = b.remove()
Buffer Class With Semaphore
class Buffer {
private int v;
private volatile boolean empty=true;
public void insert (int x) {
while (!empty)
; // null loop
empty = false;
v = x;
}
public int remove() {
while (empty)
; // null loop
empty = true;
return (v);
}
}
- The
empty boolean tells us if the buffer is empty or not.
-
volatile ensures the computer will re-load the variable each time it is tested, rather than transferring it to a register.
This says that the value could change without the compiler being aware.
- A producer will wait while the buffer is full. A consumer will wait while it is empty.
- Busy waiting (spinlock)
- This simulates the
wait operation.
- Busy waiting is inefficient
- A thread or process does nothing useful while it has the CPU.
- Spinlocks are useful only in a multiprocessor situation when expected wait time is very short.
Yielding
It may be more efficient for a waiting thread or process to relinquish control of the CPU:
public void insert (int x) {
while(!empty)
Thread.yield();
empty = false;
v = x;
}
The yield() call tells the JVM that the thread is willing to give up the CPU.
- The JVM might ignore it depending on the implementation.
- This is why it is in a
while loop so that !empty is tested many times.
- It is non-deterministic and platform dependant.
This method extends the example in the last lecture.
Java uses the American spelling: synchronized.
Synchronised Method
class Buffer {
private int v;
private volatile boolean empty = true;
public synchronized void insert (int x) {
while (!empty)
; // null loop
empty = false;
v = x;
}
public synchronized int remove() {
while (empty)
; // null loop
empty = true;
return v;
}
}
Every object has a lock associated with it.
- When a thread called a
synchronized method, it gains exclusive control of the lock.
- All other threads calling
synchronized methods on that object must idle in an entry set.
- When the thread with control exits the
synchronized method, the lock is released.
- The JVM can then select an arbitrary thread from the entry set to be granted control of the block.
Replace Spinlock with wait() and notify()
class Buffer {
private int v;
private volatile boolean empty = true;
public synchronized void insert (int x) {
while (!empty) {
try {
wait();
}
catch (InterruptedException e) {}
}
empty = false;
v = x;
notify();
}
// similarly for remove()
}
- The
wait() call:
- Stops thread execution.
- Moves the calling thread to the wait set.
- The
notify() call:
- Moves an arbitrary thread from the wait set back to the entry set.
- Depends on particular JVM implementation.
- the
notifyAll() call:
- Tells all thread in the wait set that a resource is available.
-
Threads compete for access in the same way.
The first one to call a synchronized method gets the access.
Entry & Wait Sets
flowchart BT
subgraph Runnable["Entry Set(Runnable)"]
a
b
c
end
Runnable -->|synchronized call| Lock
subgraph Lock[Object Lock]
d1["Owner (d)"]
end
Lock -->|wait| Blocked
d1 -->|notify| d
d --> Runnable
subgraph Blocked["Wait Set (Blocked)"]
d
e
f
end
Key Java Multi-Threaded Concepts
The following concepts are useful for multi-threaded programs:
Thread objects.run() method and the start() method call.volatile and synchronized keywords.yeild(), wait() and notify() method calls.
-
The producer-consumer problem models a synchronisation environment in which processes with distinct roles have to coordinate access to a shared facility.
-
The dining philosophers problem models an environment in which all processes have identical roles. Again coordinated access to shared facilities must be arranged.
Premise
$n$ philosophers spend their time seated around a table going through a routine of:
graph LR
Eat --> Think
Think --> Eat
Philosophers need nothing in order to think but, in order to eat a philosopher must use two items of cutlery (eg. 2 chopsticks).
However only $n$ chopsticks is provided:
- One between each philosopher around the table.
This means that if a philosopher is hungry but either neighbour is eating then they must wait until both chopsticks are available.
Solution
Each philosopher has a unique index value:
Similarly each chopstick is indexed from:
The philosopher with index $k$ must be able to use both the chopsticks:
\[k\cap(k+1)\mod5\]
in order to eat
Example
This means that if $P_0$ is eating, then both $P_1$ and $P_4$ will have to wait for $P_0$’s sticks to be put down.
Java Solution
The solution involves treating each chopstick as a shared resource in which access is enclosed in a critical region.
- This can be achieved via semaphores or mechanisms such as Java locks.
Code
Philosopher Thread
public void run() {
while (alive) {
think();
stick[i].get();
stick[(i + 1) % 5].get();
eat();
stick[i].put_down();
stick[(i + 1) % 5].put_down();
}
}
Chopstick Class
class Chopstick {
private volatile boolean in_use = false;
public synchronized get() {
while(in_use) {
try {
wait();
}
catch {
...;
}
}
in_use = true;
}
public synchronized put_down() {
in_use = false;
notify();
}
...
}
In comparison to a producer-consumer model, we don’t have to wait to release the resource. We also only notify() when we release the resource.
Explanation
- Each chopstick object has a lock associated with it.
- This prevents two philosophers grabbing a chopstick simultaneously.
- If a philosopher needs a chopstick, but it is already in use, the philosopher is moved into the wait set.
- When the chopstick is put down, the waiting philosopher is notified and can pick it up.
Deadlocks
Suppose each philosopher picks up the chopstick to their right simultaneously.
- Then nobody can pick up the stick on the left, and all philosophers move to the wait state.
Since nobody is releasing a stick, all philosophers wait forever.
This situation is called a deadlock.
More generally deadlock occurs in a concurrent system when each participant is waiting on others to do something.
Solution
- Allow only $n-1$ philosophers to dine simultaneously.
- Introduce asymmetry:
- Even indices pick up chopstick in order right then left.
- Odd indices use left then right.
- Insist that both chopsticks are claimed at the same time.
- In the same critical region.
All of the above complicate the code.
Starvation
- Suppose $P_0$ and $P_2$ grab their chopsticks first.
- Then $P_1,P_3$ and $P_4$ have to wait
- If $P_0$ and $P_2$ put down their stick and them immediately claim them again, the others will never eat.
- Even if $P_0$ and $P_2$ take turns, $P_1$ cannot eat.
More generally, starvation occurs when one or more of the participants in a concurrent system is denied access to resources.
A set of processes is deadlocked if each process in the set is waiting for an event only another process in the set can case.
These events usually relate to resource allocation.
Creating Deadlock
Deadlock will occur in the following simple situation:
- Process $A$ is granted resource $X$ and then requests resource $Y$.
- Process $B$ is granted resource $Y$ and then requests resource $X$.
Resource Allocation Graphs
This includes:
- Set of processes.
- Set of resource types:
- Each general type of shared resource.
- Each instance of each type.
- Set of directed edges:
Example 1
flowchart LR
subgraph R1
r11[ ]
end
subgraph R2
r21[ ]
r22[ ]
end
subgraph R3
r31[ ]
end
subgraph R4
r41[ ]
r42[ ]
r43[ ]
r44[ ]
end
r21 --> P1
P1 --> R1
r11 --> P2
r22 --> P2
P2 --> R3
r31 --> P3
No cycles, so no deadlock.
Example 2
Consider that $P_3$ now requests $R_2$:
flowchart LR
subgraph R1
r11[ ]
end
subgraph R2
r21[ ]
r22[ ]
end
subgraph R3
r31[ ]
end
subgraph R4
r41[ ]
r42[ ]
r43[ ]
r44[ ]
end
r21 --> P1
P1 --> R1
r11 --> P2
r22 --> P2
P2 --> R3
r31 --> P3
P3 --> R2
In general, a cycle indicates there could be deadlock. This doesn’t mean that there is or will be deadlock.
Dealing with Deadlock
- Prevention
- Build systems where deadlock couldn’t possibly occur.
- Avoidance
- Make decisions dynamically as to which resource requests can be granted.
- Detection and Recovery
- Allow deadlock to occur, then cure it.
- Ignore the Problem
Deadlock Prevention
There are several techniques to prevent deadlock:
- Force processes to claim all resources in one operation.
- Problem of under-utilisation.
- Process might hog a resource it no longer needs.
- Require processes to claim resources in pre-defined order.
- Resource $A$ always before resource $B$.
- Avoids processes waiting for each other.
- Grant request only if all allocated resources released first.
- Release resource $A$ before allowing claim for resource $B$.
- Avoids processes hogging resources needlessly.
Deadlock Avoidance
Requires information about which resources a process plans to use.
When a request is made, system analyses allocation graphs to see if it could lead to deadlock:
- If so, process is forced to wait.
- Can lead to reduces throughput and process starvation.
- Might not actually need to wait.
This is done by analysis of cycles.
Detection and Recovery
Ignoring Deadlock
This is the common approach for Windows, Unix, Java and others.
Why is this useful to implement:
Memory Addressing
The memory inside RAM can be viewed as a linear sequence of bytes, each with its own address.
- Addresses range from 0 up to the number of bytes available.
- Since addresses are stored in register and other variables, addressable space will depend on the bit-length of the CPU.
- 32-bit systems can address 4,294,967,296 bytes.
- This is equivalent to 4GB.
Memory
The value of the instruction pointer (IP) determines the next instruction to be fetches from memory by the CPU.
The execution of an instruction may lead to additional memory accesses.
Programs usually reside on disk as binary executable files.
In order for a program to be executed it must be brought into memory and run within a process.
When the process is executed it accesses data and instructions from memory; upon termination its memory space is freed up so it can be reused.
Address Binding
Programs require addresses for instructions and data that they want to access. There are several ways of binding these addresses.
Compile Time
This assumes that the program will always be loaded into the same memory address every time it is run.
These addresses are hard-coded into the binary.
Load-Time Binding
Ideally, programs should be able to run anywhere in memory. To do this you could:
- Generate position-independent code (PIC)
- Aided by using relative jump instructions.
JUMP -15 or `JUMP +7- These are replaced by actual values at load time.
- If not binary program files can include a list of instruction addresses that need to be initialised by a loader.
This is static for the runtime of the program.
Dynamic (Run-Time) Binding
This is the method used in modern systems:
Logical and Physical Adresses
Addresses generated by the CPU are known as logical/virtual addresses.
The set of all logical addresses generated by a program is known as the logical address space.
The addresses generated by the MMU are known as physical addresses.
The set of all physical addresses corresponding to the logical address is known as the physical address space.
- Compile and load time binding always produce the same logical and physical addresses.
- Run-time binding results in logical and physical addresses that are different.
Simple Memory Management
- Memory is allocated to program in contiguous partitions from one end of the store to the other.
- Each process has a base, or datum (where it starts).
- Each process also has a limit (length).
Filling Empty Memory
With this method you are unable to move existing programs in memory. This results in fragmentation and ineffective memory usage.
Choosing Programs
In a multiprogramming system where we have a queue of programs waiting, select a program of the right size to fit.
This has the following problems:
- Large programs may never get loaded (permanent blocking or starvation).
- Small gaps are created (fragmentation).
Avoiding Starvation
To avoid starvation, we may need to let a large program hold up the queue until enough space becomes available.
In general we have to make a choice of which selection policy to use:
- First fit:
- Choose first partition of suitable size.
- Best fit:
- Choose smallest partition which is big enough.
- Worst fit:
- Choose the biggest partition.
Fragmentation
When fragmentation is severe the following is true:
- 50% rule:
- For first-fit, if the amount of memory allocated is $n$, then the amount of unusable owing to fragmentation is $\frac 1 2 n$.
- May have to compact memory:
- Requires programs to be dynamically relocatable.
This is difficult when dealing with large programs.
Other Issues
- Shortage of Memory:
- Arising from fragmentation or anti-starvation policy.
- May not be able to support enough users.
- May have difficulty loading enough programs to obtain a good job mix.
- Imposes limitations on program structure:
- Not suitabel for shareing routines and data.
- Does not reflect high level language structures.
- Does not handle memory expansion well.
- Swapping is inefficient.
Swapping
To start more programs than can fit into physical memory a swap must be used:
- During scheduling, a process image may be swapped in, and another swapped out to make room:
- Aldo helps to prevent starvation.
- For efficiency, you may have dedicated swap space on a disk.
- This is as opposed to a swap file.
Swapping whole processes adds considerably to the time of a context switch.
This makes memory usage more efficient by only loading what part of a program is needed at any time.
The program image could consist of the following parts:
- Main program
- Different routines, classes
- Error routines
Dynamic loading allows only parts of the image to be loaded, as necessary.
When a routine calls another routine, it checks to see if it has been loaded.
- If not the relocatable linking loader is called.
This gives the advantage that unused routines are never loaded.
Linking
Linking is the integration of user code with system or 3$^{rd}$ party libraries.
- Typically done directly after the compilation process.
Static Linking
Copies of the libraries are included in the final binary program image:
- Can result in large images due to inclusion of many libraries.
- These libraries may link to more libraries.
- Wasteful both in terms of disc storage and main memory.
- Can be managed by dynamic loading, but shared libraries are still repeated in memory multiple times.
Dynamic Linking
A stub is included in the image for each library routine this indicates how to:
- Locate a memory resident library routine:
- Load the library:
Allows re-entrant code to be shared between processes:
This requires some assistance from the OS as lower level memory organisation is necessary.
Memory Organisation
To help solve some of the software problems arising from the linear store, more complex memory models are used which organise the store hierarchically:
- Segmentation
- Subdivision of the address space into logically separate regions.
- Paging
- Physical subdivision of the address space for memory management.
Segmentation is splitting up chunks of a process into logical parts.
The compiler will indicate which segment represents which logical part of the code.
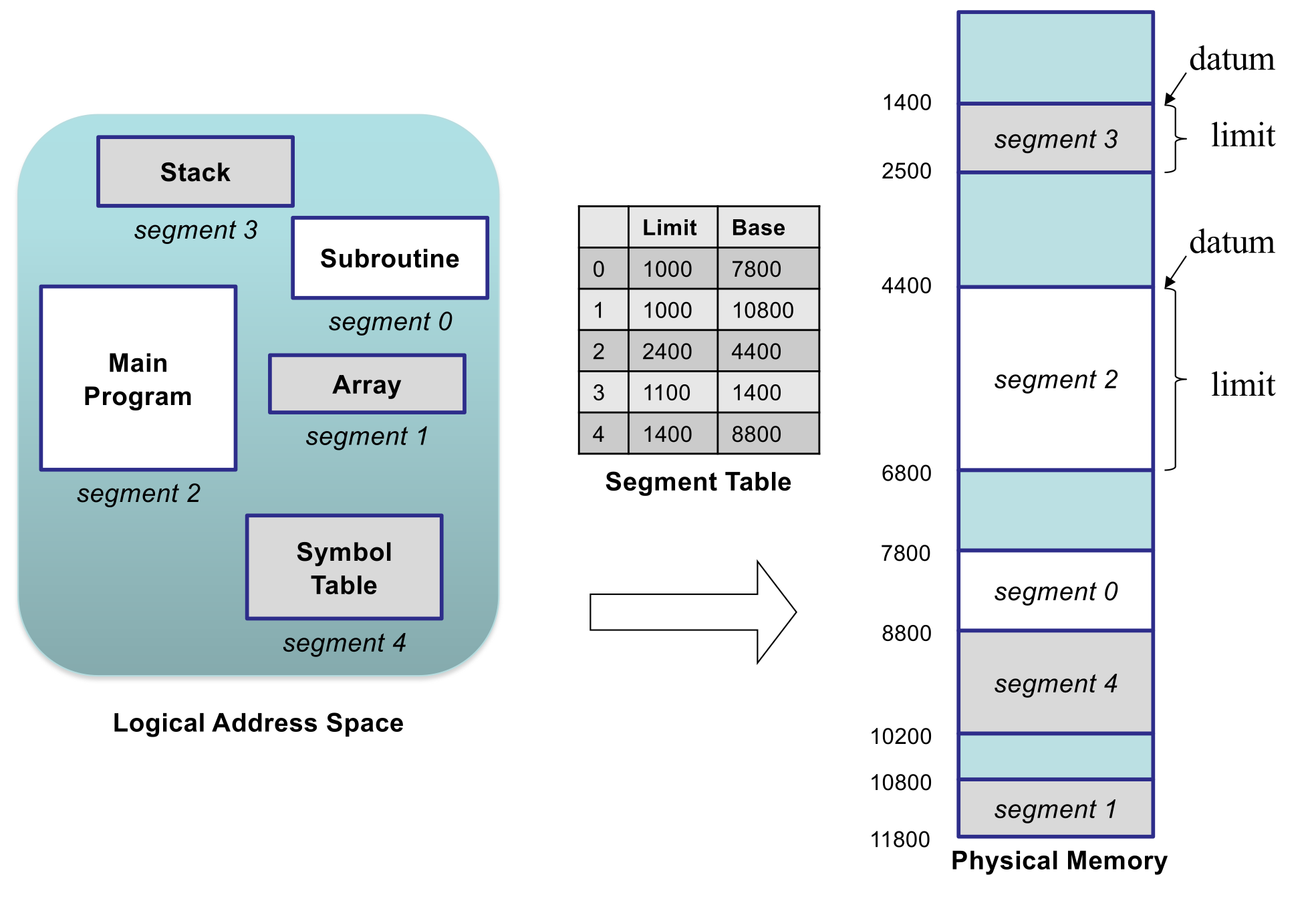
Each segment has its own partition. Segments need not be contiguous.
- These segments are able to be organised by the memory manager to fit where space is available.
- The segment table stores the locations and lengths of the segments.
- This aids fragmentation as the segments are smaller/dynamically loaded.
Segmented Address Structure
Each process has a segment table:
- Contains datum and limit vales of segments.
Address of the table is held in the segment table base register (STBR).
This is saved during context switches.
Segment Sharing
Suppose two users run the same program with different data:
graph TD
subgraph B
STB[Segment Table B]
end
subgraph A
STA[Segment Table A]
end
STA --> DataA[Data for process A]
STA --> Prog[Program code segment]
STB --> Prog
STB --> DataB[Data for process B]
-
Processes have their own data segments by can share the program code segment if it is pure (re-entrant).
Code is pure if it is not self modifying.
-
Economised on memory, so is more efficient.
Advantages of Segmentation
As the memory allocation reflects the program structure:
- It is easier to organise separate compilation of procedures.
- Protection is facilitated:
- Array bound checking can be done in hardware.
- Code segments can be protected from begin overwritten.
- Data segments can be protected from execution.
- Segments can be shared between processes.
- Large programs are broken into manageable units.
- Memory allocation is more flexible.
- Not all of a program needs to be in memory at the same time.
- Segments can be kept in swap space (disk) until needed.
- Allows more programs to be kept in memory.
- Swapping is more efficient.
Paging is the physical division of a program’s (or segment’s) address space into equal-sized blocks, called pages.
- Each page resides within a page frame in the real memory.
- Pages which are consecutive in the address space (virtual memory) need not occupy consecutive page frames in real memory.
- Very similar to the way files are stored in equal size blocks in a file system.
Page Mapping
Pages are stored in a virtual address space and are mapped to frames in real memory.
graph LR
subgraph Virtual
0[Page 0]
1[Page 1]
x[Page x]
end
subgraph Real
j[Frame J]
i[Frame I]
k[Frame K]
end
0 --> i
1 --> j
x --> k
Translation of virtual addresses (used by programs) into real addresses is performed by hardware. This is via a per-process page table.
Paged Memory
graph LR
br[Page Table Base Register]
subgraph PageTable
ptb[Beginning]
pfa[Page Frame Address]
end
br --> ptb
pfa --> pb
subgraph Page
pb[Beginning]
pa[Page Address]
end
subgraph VirtualAddress
hb[High Bits]
lb[Low Bits]
end
hb --> pfa
lb --> pa
The virtual address points to the page frame address using it’s high bits. The low bits of the virtual address are used as an offset in the page to point to the byte required.
Virtual Addressing
graph TD
subgraph VirtualAddress
vpa[Virtual Page Number]
ipa["In-page Address"]
end
This split isn’t always 50/50.
Data in memory is found from the virtual address using the following method:
- The page table is found using the page table base register (PTBR).
- Virtual page number indexes the page table to produce a real page address.
- The in-page address indexes the real bytes inside the page.
Paging Example
flowchart LR
subgraph lm [Logical Memory]
subgraph lm1 [ ]
lm0[0] --- lma[A]
1 --- lmb[B]
2 --- lmc[C]
3 --- lmd[D]
end
subgraph lm2 [ ]
lm4[4] --- lme[E]
5 -.- lmf[F]
6 --- lmg[G]
7 --- lmh[H]
end
end
subgraph va[Virtual Address]
a[10]
b[01]
end
subgraph pt[Page Table]
ptl0[0] --> ptr5[5]
ptl1[1] --> ptr6[6]
ptl2[2] --> ptr0[0]
ptl3[3] --> ptr2[2]
end
a --> ptl2
subgraph pm [Physical Memory]
subgraph 0
pm00[0] --- pme[E]
pm01[1] -.- pmf[F]
pm02[2] --- pmg[G]
pm03[3] --- pmh[H]
end
subgraph 4
pm40[0] --- pma[A]
pm41[1] --- pmb[B]
pm42[2] --- pmc[C]
pm43[3] --- pmd[D]
end
subgraph ...
end
end
ptr0 ---> 0
b --> pm01
Segmentation vs Paging
- Segmentation:
- Logical division of address space.
- Varying sized units.
- Units are visible to the program.
- Paging:
- Physical division of address space.
- Fixed-size units.
- Units bear no relation to program structure.
Either may be used a a basis for a swapping system.
Memory could be both segmented and paged via the use of multiple tables.
Advantages of Paging
- Fixed-size units make space allocation simpler.
- Normal fragmentation is eliminated.
- There is some internal fragmentation (space wasted within frames).
Intel x86 MMU
This feature supports segmentation with paging:
- CPU generates logical addresses, which are passed to the segmentation unit.
- The segmentation unit produces a virtual address, which is passes to the paging unit.
- The paging unit generates physical addresses in main memory.
The CPU is doing this every time an instruction needs to access memory to get or store some data.
Virtual Memory
The logical address space doesn’t have to match the address space of physical memory. This allows us to allocate more memory to processes than there is physical memory in the system.
This is possible by using paging:
- Not all pages need to be in memory.
- Unneeded pages can reside on disk.
- Memory becomes virtual as it is not restricted by physical memory.
Page Faults
Page faults occur when a process references a page that is not in main memory.
This is not an error.
Page faults generate an interrupt because address references cannot be satisfied until the page is swapped in from disk.
The OS response is normally to fetch the page from the disk (demand paging).
Page Replacement Problem
The page replacement problem occurs when we don’t have enough room for a fetched page.
A solution is to swap out a page from physical memory. If this is chosen poorly then persistent swapping (thrashing) will occur.
Page Replacement
The optimal policy is to swap out the page that will not be needed for the longest time.
To estimate this we use the principle of locality:
Over any short period of time, a program’s memory references tend to be spatially localised.
This means that future memory access is likely to be around the most recently accessed memory.
Working Set Model
The principle of locality defines:
- Execution doesn’t tend to jump all over the place.
- Array access will be in the same region of memory.
- Code within a loop will sped time in the same region.
- Generally, 80% of execution stays within 20% of the code.
The working set fo a process is define to be the set of resources (pages) $W(T,s)$ defines in the time interval $[T,T+s]$.
This is to say that $W(12,4)$ is the working set in the time period from 12 to 16.
Example
For the following working set:
| Pages |
z |
a |
b |
A |
A |
A |
Z |
b |
b |
a |
| Time |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
-
The working set for $W(3,3)$ is $\{a,z\}$.
We count all the pages that are in capitals. This is the third page (represented by the first number) and the three proceeding pages (represented by the second number).
By the principle of locality, the working set for the next time period is likely to be similar to the one for the current period.
Hence for each process:
- Try to ensure it’s working set is in memory.
- Estimate the next working set by recording the set of pages referenced in the preceding time interval.
-
The predicted working set for $W(10,2)$ is $\{a,b\}$.
We look two spaces back from the point specified. These are elements 8 and 9.
Issues
The accuracy of the working set depends on its size:
- If it is too small, it will not cover the entire locality.
- If it is too large, it will cover several localities.
Over time the working set of a process will change as reference to data and code sections move from one locality to another.
- Page fault rates will vary with these transitions.
Other Policies
There are replacement policies for use with demand paging, based loosely on working set principles:
- Least recently used (LRU)
- Replace the leased recently used page.
- First in first out (FIFO)
- Replace the page which has been in memory the longest.
- Least frequently used (LFU)
- Replace the page with the fewest reference in a recent time period.
These methods are covered more in-depth in the COMP108 - Assignment 1 introduction.
Frame Allocation
There is a fixed amount of free memory that must be allocated among all processes.
- We needed to determine how many frames each process should get.
Each process will need a minimum number of pages.
- This is dependant on the architecture and its supported features.
Frames contain a number of pages.
Allocation Schemes
- Equal Allocation:
- Each process gets an equal share of frames.
- Proportional Allocation:
Segmentation and paging overcomes may limitations of a linear store model but:
- There is a performance hit:
- Each memory reference may require 2-3 memory access from table lookups.
Special hardware may help:
- Registers to hold the base address of the current code and data segments may allow tables to be bypassed.
- Special memory can aid fast table lookup:
Page Size
Large Pages
- A large page size means a smaller page table.
- However large pages mean more wastage:
- 50% of a page per process is lost due to internal fragmentation.
Small Pages
- Small pages give better resolution.
- Can bring in only the data that is needed fro the working set.
- Small pages increase the chances of page faults.
Memory Hierarchy

Cache Memory
Efficiency can be maximised by keeping data as close to the CPU as possible:
- Registers are the best, but only few are available.
- Main memory is comparatively slow.
- Cache memory is small, fast memory that sits between the CPU and main memory.
- It contains copies of items in main memory.
When the CPU needs information, it first checks the cache.
The Java volatile keyword prevents cache usage.
- If an item is found we have a cache hit.
- If not, we have a cache miss.
- The block of data containing the requested item is copied into cache.
By the principle of locality, it is likely that future items will now be in cache.
- May have two or more levels of cache.
- May have separate caches for instructions and data.
Compilers
- Take a source program and translates it as a whole into machine code.
- The process of translation and execution are separate.
Interpreters
- Take one instruction at a time, determine its function and then carries out those instructions.
- Source program analysis and execution are interlaced.
- No binary is generated.
Compilers vs. Interpreters
- Execution of compiled code is much faster than interpretation.
- Interpreters are more suitable for rapid prototyping and for other situations where the program is frequently modified.
- Interpretation can make it easier to move programs between platforms.
- Interpreters may be easier to write than compilers.
- Interpreted code is easier to debug.
Interpreters as Virtual Machines
An interpreter is somewhat similar to a CPU:
- Takes one instruction at a time and carry out the actions it specifies.
because of that they are sometimes referred to as a virtual machine.
Some systems combine compilation and interpretation:
- HLL is converted to machine independent virtual machine code.
- Virtual code is then interpreted on each platform.
Example - Java
- The Java compiler generated virtual bytecode.
- This is then interpreted by the JVM (Java virtual machine).
Translation
Turning your source code into binary (machine code) that the CPU can understand is usually done by special programs such as:
- Compilers, translating HLL instructions into machine code.
- Assemblers, translating mnemonic form of machine instructions (assembly code) into their binary code.
Some compilers generate assembly code which is then passed to an assembler as a separate stage.
Some compilers generate the binary code directly.
Translation Process
graph LR
edit[[Editing Code]] --> HLL[(HLL Source File)]
HLL --> Compile
Compile --> errors1[Errors]
Compile --> bin[(Binary Object Files)]
bin --> Link
lib[(Library Files)] --> Link
Link --> errors2[Errors]
Link --> exe[(Executable File)]
exe --> Load
Load --> Run
Each HLL has three components:
- Lexical Components (tokens)
- Syntactical Components (structure)
- Semantic Components (meaning)
Lexicon
The lexical component is a list of all the legal words (elementary expressions) in the language, together with information about each word.
Example
In Java import, public and else are legal words. They go together with information about their meanings and roles.
Syntax
The syntax defines the form and structure of legal expressions of the language
Example
In Java:
is not a correct fragment of code. It is lexically correct but not syntactically.
Semantics
The semantic component deals with meaning of the expressions.
In programming languages, the semantic component defines a course of action to be performed when executing a particular fragment of a program.
Example
In Java, the fragment:
if (m < n)
System.out.println("The minimum is " + m);
means:
Check if $m<n$. If it is true, then print the message, otherwise skip this instruction.
Programming Language Description
The precise description of a programming language is needed for the translator to:
- analyse the source code;
- generate correct and unambiguous code.
A key part of the precise description of any programming language is the syntax rules that make up its grammar.
This is an English language description of the language:
Pascal is written free form with no required layout. Tokens are separated by space, tabs, carriage returns, or comments. The basic Pascal structure is the block. A block consists of the following components:
label declarations
constant definitions
...
procedure and functions declarations
program statements
...
- It is easily understandable by a human and it is useful as a reference source.
- It is not precise and unambiguous enough to be used by a compiler or interpreter.
- We need a much more formal way to define the correct syntax of a language.
A grammar is a set of syntactic rules. Syntactic rules define syntactic constructions in terms of other syntactic constructions:
- Some of which need to be defined themselves.
- Some of which are already defined.
Constructions can be terminal (self-contained), or non-terminal (depend on other constructions).
Hierarchy
- A grammar defined correct sentences (programs) in terms of elementary parts (symbols).
-
Symbols are formed into tokens, which have meaning within the syntax of the language.
A token is the smallest group of character symbols that has a specific meaning within the language.
Syntax Diagrams
We can represent the syntax rules as a set of diagrams:
graph LR
ifelse["if-else"] --> if(if)
if --> l("(")
l --> be(Boolean Expression)
be --> r(")")
r --> cb(Code Block)
cb --> done(( ))
cb --> else(else)
else --> cb2(Code Block)
cb2 --> done2(( ))
graph LR
cb[Code Block] --> s1(Statement)
s1 --> done(( ))
cb --> l("(")
l --> s2(Statement)
s2 --> s2
s2 --> r(")")
r --> done
In these diagrams there are two types of expressions:
- Non-terminal expressions (defined by rules):
- if-else
- Boolean Expression
- Code Block
- Statement
- Terminal expressions (in final form):
An alternative and more precise method for describing the grammar is known as Backus-Naur form (BNF).
The rules of the language are representing in BNF in the form of productions like so:
non-terminal $\rightarrow$ sequence of non-terminal and terminal symbols (expressions)
Example
<if-else> -> if <lbracket><expression><rbracket><code block>[else <code block>]
<code block> -> <statement> | <lbracket><statement>+<rbrace>
This is extended BNF.
The following is valid notation:
| Notation |
Description |
| $\rightarrow$ |
Rule Definition. |
| | |
Or |
| <name> |
Non-terminal Symbol |
| [tokens] |
Optional Symbols |
| {tokens} |
Symbols repeated 0 or more times. |
| * |
Symbols repeated 0 or more times (suffix). |
| + |
Symbols repeated 1 or more times (suffix). |
Example
This example defines that a varname must start with a letter and may have any number of letters or numbers for the rest of the name.
<varname> -> <letter>{<letter>|<digit>}
<letter> -> a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z
<digit> -> 0|1|2|3|4|5|6|7|8|9
| Valid |
Invalid |
| zbc99 |
7gbh8 |
| a9fg28p |
89de8w45x |
Parsing
The description of the grammar of a programming languae can consist of lots of rules (the grammar for Java contains around 120 rules).
Given a grammar, a parsing of a program in the language deigned by that grammar consists of determining which of the productions applies in a particular place as one analyses the program.
- If the program cannot be obtained by the grammar rues, the it is incorrect - there are syntactical mistakes.
The compiler will attempt to show where the error is, by often the parse error happens some way from the actual cause of the problem.
The Compilation Process
The compilation process is normally broken down into the following major steps:
- Lexical Analysis
- Syntax Analysis (Parsing)
- Semantic Analysis
- Code Generation
- Code Optimisation
Lexical Analysis
The text of the program is converted into a sequence of tokens, representing distinct elements of the program:
- Numbers
- Letters
- Symbols
- Variable Names
- Keywords
As they are encountered, identifiers are entered into a symbol table containing:
- Variable Names
- Class Names
- Function Names
- Any other name created by the programmer.
Syntax Analysis (Parsing)
The soruce program is analysed to uncover the grammatical form of the costructions used.
The aim is to group and structure the tokens in a way which identifies the kinds of program constructs:
- Declarations
- Loops
- Other constructs
Scanning and Parsing
The scanner and parser work together:
graph LR
sf[Source File] -->|Input Stream| Scanner
Scanner -->|Tokens| Parser
Parser -->|Parse Tree| a(( ))
- The scanner uses regular expressions to define tokens.
- BNF rules define the parser’s grammar elements.
Example
For the following source file:
The scanner splits it into the following tokens:
The parser will make the following parse tree from those tokens:
graph TD
sum --> =
= --> +
+ --> x1
+ --> x2
Semantic Analysis
-
In this phase, information is built up in the symbol table about the data items being declared:
- Variables
- Arrays
- Other data items.
Memory locations will be assigned for each variable.
-
Checks are performed for type consistencies.
In strongly typed languages, this is where types are checked.
-
The compiler will show error messages if is sees problems at this stage.
Code Generation
-
Code will be generated for each of the construct identified during the syntax and semantic steps:
- Loops
- Conditions
- Method Calls
These all have to be stored in the parse tree.
- Walk through the parse tree and generate low-level (machine) code for each aspect of the tree.
- Moving node by node through the tree will generate the code in the right order.
Code Optimisation
The code is analysed to determine if there are ways to:
- Reduce the amount of code.
- Eliminate repeated operations.
- Reorganize parts of the program to execute faster.
Optimisation can happen in multiple places:
- Scanning
- Parsing
- Code Generation
Example
Removing loop-invariant code:
for (int i = 0; i <= n; i++) {
x = a + 5; // doesn't rely on the loop
System.out.println(x * i);
}
Becomes:
x = a + 5;
for (int i = 0; i <= n; i++) {
System.out.println(x * i);
}
This saves redundant execution cycles for setting the variable x.
Question 1 - Memory Management Unit
Which component of the CPU manages the storage and retrieval of data from main memory?
Look here for more information about memory management.
Question 2 - Principle Components of an Operating System
Which of these is not one of the four principal components of an operating system?
The principle components are:
- Memory Manager
- Processor Manager
- Device Manager
- File Manager
For more information see Operating Systems Overview.
Question 3 - Virtual Memory Location
Where is virtual memory is located?
Swap partitions are used in Linux to hold virtual memory (swap space). They virtual memory can also be stored in a file (as in Window’s page file, or Linux’s swap file).
See Swapping from Memory Fragmentation.
Question 4 - Process Scheduling
Consider the pool of processes below, which arrive in the order listed. What will be the average wait time if the CPU is allocated to processes using a FCFS scheduling policy?
- $P_1$ has a burst time of 6 ms.
- $P_2$ has a burst time of 10 ms.
- $P_3$ has a burst time of 2 ms.
- $P_4$ has a burst time of 8 ms.
- $P_5$ has a burst time of 12 ms.
NOTE: If you attempted this question before 12:25 on 13th May, ALL answers below were incorrect due to a typo on my part. Sorry about that. There is now ONE correct answer below.
(I can absolutely assure you that the REAL exam has been triple checked by multiple people, and there is one correct answer for each question!)
This can be modelled with the following Gantt chart:
gantt
dateformat S
axisformat %S
P1: a, 0, 6s
P2: b, after a, 10s
P3: c, after b, 2s
P4: d, after c, 8s
P5: e, after d, 12s
This gives the following wait times:
- 0 milliseconds for $P_1$.
- 6 milliseconds for $P_2$.
- 16 milliseconds for $P_3$.
- 18 milliseconds for $P_4$.
- 26 milliseconds for $P_5$.
This would give the following average wait time:
\[\frac{0+6+16+18+26}{5}=13.2\text{ms}\]
For more examples see the following:
Which of these strings does not match <S> in the EBNF grammar shown below?
<S> $\rightarrow$ {<D>|<U>}<L><U> $\rightarrow$ A|B|C|D|E<L> $\rightarrow$ v|w|x|y|z<D> $\rightarrow$ 0|2|4|6|8
This table explains the EBNF notation.
DA6 is the only one which doesn’t match as it doesn’t end with a character from v-z. The <L> section is not wrapped in {} meaning that it is not optional.
Question 6 - Register Names
Which one of the following is not a valid register name within a 32-bit Intel x86 CPU?
I just used Ctrl + f to search through COMP124. The valid registers listed are:
- ESP - Stack Pointer
- EBP - Base Pointer
- ECX - C Register (used for counting loops)
- EIP - Instruction Pointer
All of these registers are the 32-bit versions.
Question 7 - Assembly Operand Addressing Modes
Which one of the following is not an assembly language operand addressing mode?
See Addresssing Modes. This refers to the forms that operands can take.
Question 8 - Assembly Program 1
What decimal value will be stored in the accumulator after the following assembly code fragment has been executed?
asm: mov ebx, 8
cmp ebx, 5
jg one
mov eax, 2
jmp end
one: mov eax, 1
end: push eax
Follow the flow of execution (EAX is the accumulator):
| Line |
EAX |
EBX |
Greater |
| 1 |
|
8 |
|
| 2 |
|
8 |
True |
| 3 |
|
8 |
True |
| 6 |
1 |
8 |
|
| 7 |
1 |
8 |
|
The EFLAGS register is used when comparing two values, see Comparing Values. This triggers the jg instruction if the first operand is greater.
Question 9 - Assembly Program 2
Which one of these statements is false when the instructions below are executed on a 32-bit system?
mov ebx, 2
mov eax, 45
push ebx
push eax
The stack grows downward in memory so therefore the stack pointer moves 8 bytes lower not higher.
As for why the others are true:
- There is no context switch, so the base pointer is unchanged. Only the stack pointer moves when adding values to the stack.
- Registers remain unchanged when their values are moved to the stack (EBX is the base register).
- The top of the stack is always the most recent value. EAX, which holds 45, was last pushed to the stack so the top holds this value.
- Each register is 4-bytes (32-bits) long, so adding two 4-byte values to the stack grows it by 8-bytes.
Question 10 - Thread.yield() Multi-Threading
Which one of these statements is false when considering the behaviour of the Java Thread.yield() method?
See Yielding. Any thread is able to yield.
Question 11 - Working Sets (Principle of Locality)
What is the working set W(2,4) in this sequence of page references?
| Page |
a |
a |
b |
a |
a |
c |
a |
d |
d |
e |
| Time |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Start at 2 and then count forward 4, which gives you 5 elements: $b, a,a, c, a$. As sets don’t have repeating elements this gives the set of: $\{a, b, c\}$. For another example see here.
Question 12 - Network Topologies
How many paths would be required to fully connect 5 devices in a point-to-point system?
This is the same as a mesh topology. You can draw it out and count the paths:
graph LR
a ---|1| b
b ---|5| c
d ---|10| e
c ---|9| e
b ---|6| d
c ---|8| d
b ---|7| e
a ---|2| c
a ---|3| d
a ---|4| e
or calculate:
\[4+3+2+1=10\]
which represents the number of unique paths connecting each node to every other node.