Introduction
The lecturer for this subject is Prof. Prudence Wong. Email is pwong@liverpool.ac.uk.
The lecturer for this subject is Prof. Prudence Wong. Email is pwong@liverpool.ac.uk.
An algorithm is a precise and concise set of instructions that guide you to solve a specific problem in a finite amount of time.
graph LR
Input --> Algorithm
Algorithm --> Output
The differences between algorithms and programs are as follows:
This is a logical code that doesn’t strictly follow the syntax of any individual programming language. They are useful for drafting algorithms.
Pseudo code uses a combination of english and code to make it more human readable.
The following conventions for pseudo code are preferred:
if <condition> then
<statement>
else
<statement>
for <variable> <- <value1> to <value2> do
<statement>
while <condition> do
<statement>
Block in control sequences should be laid out like so:
begin
<statement1>
<statement2>
.
.
.
end
or:
{
<statement1>
<statement2>
.
.
.
}
% operator can be used in place of mod.The use of a boolean variable to mark a significant event is called a flag variable. You can use this to mark a condition that has been met.
It is recommended that you draw a trace table of all the values at each iteration to find logical errors in your algorithms. You can also use them to find out what an algorithm does.
This lecture follows through some examples of solving particular problems in pseudo code. The slides for this lecture are available here.
In this example we find the factors of $x$ and $y$ and subtract the elements in the $y$ list from the $x$ list.
This example iterates through all numbers until it finds one that satisfies mod = 0 for both numbers.
Using breaks in a loop is not a good practice as it diminishes readability.
Efficiency matters as we want to make more ambitious code to leverage increases in computational power. If we didn’t optimise code then we’d be wasting resources.
Timing execution time is not enough as it is not reproducible and wastes time.
We should identify some important operations and count how many times these operation need to be executed.
We can then change the input size and see how the time the algorithm takes changes.
Assume this initial scenario:
Now suppose that Computing speed increases by a factor of 100:
We show here that an $n^2$ comparison algorithm gives a 10 times speed increase with a raw 100 times speed increase.
Here is an algorithm:
sum = 0
i = 1
while i <= n do
begin
sum = sum + i
i++
end
output sum
The important operation of summation is addition.
For this algorithm we need $2n$ additions (dependant on the input size of $n$).
This question may be dependant on the input size you may want to use several algorithms:
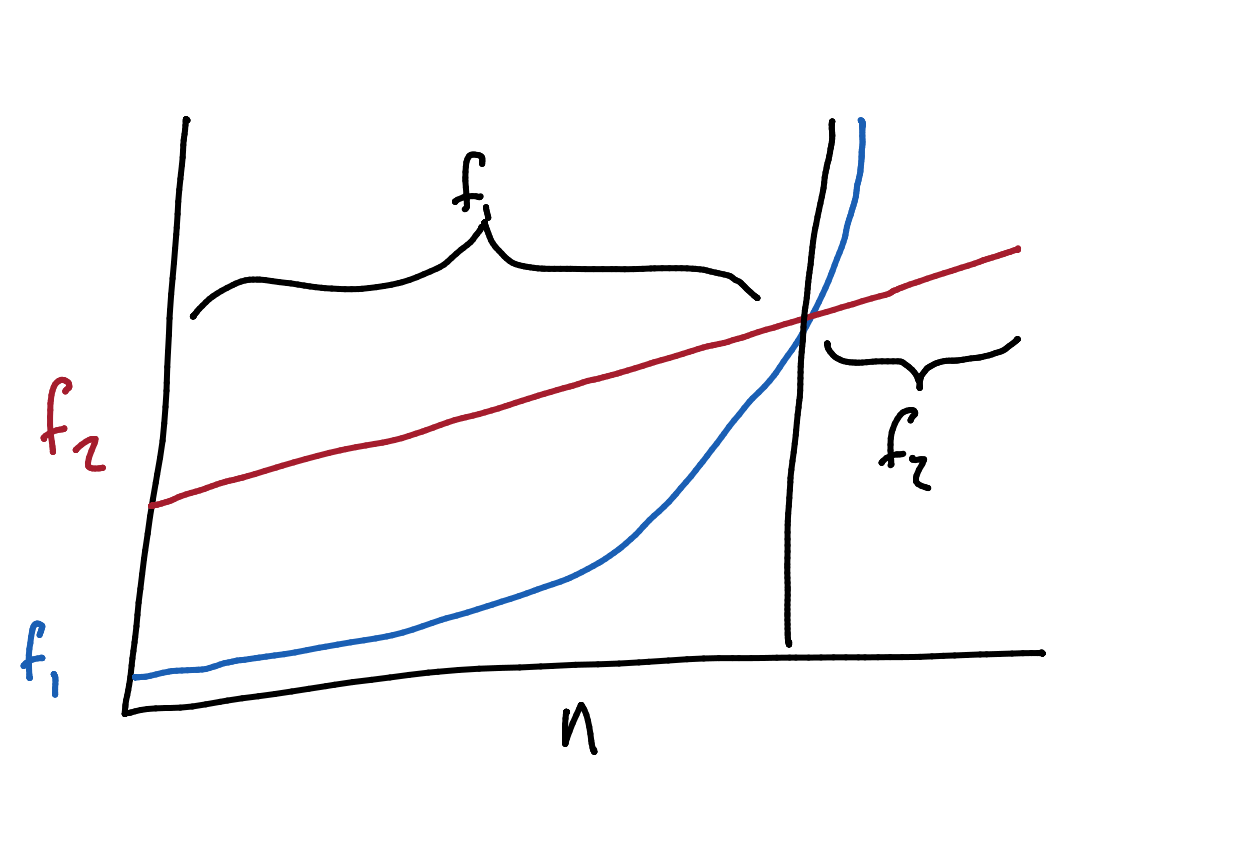
Generally you would want to choose the most efficient algorithm for when the input is maximal. In this example you would choose $f_2(n)$.
Here are functions ordered by their growth rate:
In computer science $\log$ refers to $\log_2$.
Comparing $\log^3n$ and $n$.
Identity: \(n\equiv 2^{\log_2n}\)
As $\log^3n$ is polynomial in terms of $\log n$ and $n$ (by the identity) is exponential in terms of $\log n$ the former is lower in the hierarchy.
Similarly, $\log^kn$ is lower than $n$ in the hierarchy, for any constant $k$.
\(f(n) =O(g(n))\)
Read as $f$ of $n$ is of order $g$ of $n$.
Roughly speaking, this means that $f(n)$ is at most a constant times $g(n)$ for all large $n$:
When we have an algorithm, we can then measure its time complexity by:
To find the time complexity of an algorithm look at the loops:
count = 0
for i = 1 to x do
for j = 1 to y do
for k = 1 to z do
count = count + 1
For this loop the time complexity is $O(xyz)$. You can see that the variable relates to the time complexity.
Here is another example:
i = 1
while i <= n do
begin
j = i
while j <= n do
j = j + 1
i = i + 1
end
The time complexity for this loop is $O(n^2)$. This is as a result of the time complexity of:
\[\frac{n\times(n+1)}{2}\]The highest term in this equation is $n^2$.
Here is another algorithm:
i = 1
count = 0 while i < n do
begin
i = i * 2
count = count + 1
end
output count
This is the trace table for this algorithm:
Suppose $n=8$
| Iteration | i before |
i after |
count |
|---|---|---|---|
| Before Loop | 1 | 0 | |
| 1 | 1 | 2 | 1 |
| 2 | 2 | 4 | 2 |
| 3 | 4 | 8 | 3 |
Suppose $n=32$
| Iteration | i before |
i after |
count |
|---|---|---|---|
| Before Loop | 1 | 0 | |
| 1 | 1 | 2 | 1 |
| 2 | 2 | 4 | 2 |
| 3 | 4 | 8 | 3 |
| 4 | 8 | 16 | 4 |
| 5 | 16 | 32 | 5 |
We can see by comparing $n$ to the iterations that this algorithm is not linear.
To find the count that gives $n$ we would need to calculate:
\[2^\text{count}=n\]Therefore this algorithm has logarithmic time complexity:
\[O(\log n)\]Don’t presume, when you see a loop, that the time complexity is polynomial.
For arrays, out of bounds means any index that is not in the range of the index.
When using arrays in pseudo code the following notation will be used:
arrayName[index]
Arrays in the notes will also be indexed from 1.
$n$ numbers stored in an array A[1..n], and a traget number key.
Determine if key is in the array or not.
i = 1, coparte key with A[i] one by one as long as i <= n."Found" when key is the same as A[i]."Not Found" when i > n.| 12 | 34 | 2 | 9 | 7 | 5 |
|---|---|---|---|---|---|
| 7 |
| 12 | 34 | 2 | 9 | 7 | 5 |
|---|---|---|---|---|---|
| 7 |
| 12 | 34 | 2 | 9 | 7 | 5 |
|---|---|---|---|---|---|
| 7 |
| 12 | 34 | 2 | 9 | 7 | 5 |
|---|---|---|---|---|---|
| 7 |
| 12 | *34 | 2 | 9 | 7 | 5 |
|---|---|---|---|---|---|
| 7 |
Found
i = 1
found = false
while i <= n AND found == false
begin
if A[i] == key then
found = true
else
i = i + 1 // Don't increment if number is found to save i.
end
if found == true then
output "Found"
else
output "Not Found"
How many comparisons does this algorithm take?
key is the first element in the list.key is not in the array or the key is the last number.This method is a moire efficient way of searching but only when the sequence of numbers is sorted.
A sequence of $n$ sorted numbers in ascending order and a target number key.
key with number in the middle.key is smaller or greater than the middle number.| 3 | 7 | 11 | 12 | 15 | 19 | 24 | 33 | 41 | 55 |
|---|---|---|---|---|---|---|---|---|---|
| 24 |
Go for lower if there is no middle. Consistency is key.
| 19 | 24 | 33 | 41 | 55 | |||||
|---|---|---|---|---|---|---|---|---|---|
| 24 |
| 19 | 24 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 24 |
| 24 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 24 |
Found
If the key is not in the array you can conclude the number is not there when comparing to the last digit.
first = 1
last = n
found = false
while first <= last && found == false do
begin
mid = floor((first + last) / 2)
if A[mid] == key then
found == true
else if A[mid] > key then // these two cases will trip first <= last
last = mid - 1
else A[mid] < key
first = mid + 1
end
if found == true then
output "Found"
else
output "Not Found"
This search is generally quicker than linear search.
key is the middle number.key is not in the list.This is as every comparison reduces the amount of numbers by at least half. We are asking: “How many times are we dividing $n$ by 2 to get 1?”
This assignment is based around memory management.
Two level virtual memory system
Slow memory contains more pages than fast memory called cache.
Requesting a page:
In case of a miss, need to evict a page from cache to make room: eviction algorithms
Nothing is evicted with the cache containing exactly what it contains initially.
In the case of a miss the first element in the cache will be evicted first. This is similar to a queue.
| 20 | 30 | 10 |
|---|---|---|
| 5 | 20 | 10 |
Second row is after the request sequence.
If there is more than one page with lowest frequency, evict the leftmost one.
| Cache | Frequency | Explanation |
|---|---|---|
| 20 30 10 | 1 1 1 | Initial cache. |
| 20 30 10 | 2 1 1 | Frequency of 20 increased. |
| 20 30 10 | 2 2 1 | Frequency of 30 increased. |
| 20 30 5 | 2 2 1 | 5 is a miss, evict 10 (freq of 1). |
| 20 30 5 | 2 3 1 | Frequency of 30 increased. |
| 20 30 5 | 2 3 2 | Frequency of 5 increased. |
| 20 30 5 | 3 3 2 | Frequency of 20 increased. |
We look forward in the request queue and replace the item in the cache that is furthest forward. If there is more than one page with same position of next request $\infty$ evict, leftmost one.
| Cache Before | Cache After | Position of Next Request |
|---|---|---|
| 20 30 10 | 1 2 $\infty$ | |
| 20 30 10 | No change. | 6 2 $\infty$ |
| 20 30 10 | No change. | 6 4 $\infty$ |
| 20 30 10 | 20 30 5 | 6 4 5 |
| 20 30 5 | No change. | 6 $\infty$ 5 |
| 20 30 5 | No change. | 6 $\infty$ $\infty$ |
| 20 30 5 | No change. | $\infty$ $\infty$ $\infty$ |
If the dataset is sorted in descending order then the first number is the maximum number.
This is excessive if set is unsorted.
i = 1
m = 0 # only works for +ve numbers; see next example
while i <= n do
begin
if A[i] > m then
m = A[i]
i++
end
output m
i = 1
m = A[1] # initialise to the first number in the array
while i <= n do
begin
if A[i] < m then # this comparison is changed
m = A[i]
i++
end
output m
The time complexity of this algorithm is:
\[O(n)\]This is as it iterates through every item in the list once.
i = 2 # location of second
loc = 1 # location of first
while i <= n do
begin
if A[i] > A[loc] then
loc = i
i++
end
output loc and A[loc]
This will find the location of the first instance of the largest number.
To find the location of the last location you would use the following:
i = 2 # location of second
loc = 1 # location of first
while i <= n do
begin
if A[i] >= A[loc] then
loc = i
i++
end
output loc and A[loc]
This will update if we come to a new instance of the maximum value.
Find the first maximum:
m = A[1]
i = 2 # compare A[1] with A[2] in first iteration
while i <= n do
begin
if A[i] > m then
m = A[i]
i = i + 1
end
Then print other locations of m:
i = 1
while i <= n do
begin
if A[i] == m then
output i
i = i + 1
end
output M
m1 = max(A[1],A[2]) # ensure correct order
m2 = min(A[1],A[2])
i = 3 # skip comparing already compared
while i <= n do
begin
if A[i] > m1 then
begin
m2 = m1
m1 = A[i]
end
else if A[i] > m2 then
m2 = A[i]
i = i + 1
end
output m1 and m2
There is one loop with a constant number of comparisons. This gives a big-$O$ notation of:
\[O(n)\]Suppose we have data of daily rainfall for a year. Find the maximum monthly average rainfall over a year.
We could store rainfall data in a 2D array of size $m\times d$:
| 1 | 2 | … | $d$ | |
|---|---|---|---|---|
| 1 | ||||
| 2 | ||||
| … | ||||
| $m$ |
rainfall[i][j] stores rainfall of month $i$ and day $j$.
You can split the problem into the following questions:
j = 1
sum = 0
while j <= d do
begin
sum += rainfall[i][j] # ask for i
j++
end
average = sum / d
This is the nested portion of the loop. $i$ should be incremented outside.
m = 0
i = i
while i <= m do
begin
sum = 0
for j = 1 to d do
sum += rainfall[i][j]
average = sum / d
if average > m then
m = average
i++
end
output m
The nested portion has a time complexity of $O(d)$. This is repeated $m$ times giving an overall time complexity of:
\[O(m\times d)\]There are two operations on a queue:
The head points to the first element and the tail points to the location where data should be enqueued.
The actions are completed as follows:
Q[tail] and increment tail by 1.Q[head] and increment head by 1.Need to check if queue is empty before dequeue or full before enqueue.
Enqueue(Q,x)
Q[tail] = x
tail++
Dequeue(Q)
if head == tail then # both pointers at same place
Queue is EMPTY
else begin
x = Q[head]
head++
return x
end
Enqueue(Q,x)
if tail > size then
Queue is FULL
else begin
Q[tail] = x
tail++
end
In order to make use of free lower blocks the indexes must wrap around. This will give the following methods:
tail, if it exceeds size, then reset it to 1.size - 1 you can use %.head, if it exceeds size, then reset it to 1.size - 1, you can use %.The following are the operations on stacks:
The stack has one pointer that points to the top-most data in the stack.
top by 1 and save the data to S[top].S[top] and decrement top by 1.You need to check if the stack is empty before popping and the opposite for pushing.
Push(S,x)
top++
S[top] = x
Pop(S)
if top == 0 then
stack is EMPTY
else
begin
x = S[top]
top--
return x
end
Push(S,x)
if top == size then
stack is FULL
else
begin
top++
S[top] = x
end
You can use the stack to compute mathematical operations. This is the case if you use reverse Polish notation. This style of notation makes the precedence implicit.
Evaluate 10 3 2 * - 5 *
| Expression | Stack |
|---|---|
| 10 3 2 * - 5 * | |
| 3 2 * - 5 * | 10 |
| 2 * - 5 * | 10, 3 |
| * - 5 * | 10 , 3, 2 |
| - 5 * | 10, 6 - Push top two, complete operand, push result. |
| 5 * | 4 - Push top two, complete operand, push result. |
| * | 4, 5 |
| 20 - Push top two, complete operand, push result. |
Whenever an operator is popped, output it.
Linked lists are lists in which elements are arranges in a linear order. The order is determined by a pointer (rather than array indices).
Each node has a data field and one/two pointers linking to the next/previous element in the list.
Nodes with one pointer are called singly linked and ones with two are called doubly linked.
graph TD
subgraph node
prev --> a[ ]
data --> b[15]
next --> c[ ]
end
We refer to the three objects as: node.data, node.next and node.prev:
node.next is NIL.node.prev is NIL.head points to the first nodetail points to the last node.The difference between linked lists and arrays is that you must follow the pointers to get to the data and can’t just go straight to a particular index.
graph LR
head --> prev1[ ]
subgraph 1
prev1[prev]
15
next1[next]
end
next1 --> prev2
subgraph 2
prev2[prev]
10
next2[next]
end
next2 --> prev3
subgraph 3
prev3[prev]
20
next3[next]
end
next3 --> tail
Traversing and outputting each element of a linked list:
node = head
while node =/= NIL do
begin
output node.data # output the data from this node
node = node.next # go to next node
end
Searching if the value key is in a linked list:
node = head
found = false
while node =/= NIL AND found == false do
begin
if node.data == "key" then
found = true
else # this keeps the node in the case that the element is found.
node = node.next
end
if found == true then
output "Found!"
else output "Not found!"
node = head
while node =/= NIL AND node.data =/= "key" do
node = node.next
if node == NIL then
output "Not found!"
else output "Found!"
The time complexity of these two algorithms are:
\[O(n)\]We are unable to use a binary search to find elements in a linked list as we have to walk the list. We are able to end the search if the data overshoots the requested data:
node = head
while node =/= NIL AND node.data < "key" do
node = node.next
if node == NIL then # must check for NIL to avoid reading empty node
output "Not found!"
else if node.data == "key" then
output "Found!"
else output "Not found!"
The time complexity of this algorithm is:
\[O(n)\]List-Insert-Head(L,node)
node.next = head
node.prev = NIL
if head =/= NIL then
head.prev = node
else // list was empty
tail = node
head = node
List-Insert-Tail(L,node)
node.next = NIL
node.prev = tail
if tail =/= NIL then
tail.next = node
else // list was empty
head = node
tail = node
Suppose we want to insert a node after a node pointed to by curr.
# assume that curr is pointing to a node
List-Insert(L,curr,node)
node.next = curr.next
node.prev = curr
curr.next.prev = node # points to new position from old next
curr.next = node # point to new position from prev
This will not work if curr is at any end.
The time complexity of:
Consider a list 15, 10, 20. We want to remove 15 and return it to the user.
List-Delete-Head(L)
node = head
if node =/= NIL then
begin // list wasn't empty
head = head.next
if head =/= NIL then
head.prev = NIL
node.next = NIL
end
return node
Consider a list 15, 10, 20. We want to remove 20 and return it to the user.
List-Delete-Tail(L)
node = tail
if tail =/= NIL then
begin // list wasn't empty
tail = tail.prev
tail.next = NIL
node.prev = NIL
end
return node
Consider a list 15, 10, 20. We want to delete a node pointed to by curr and return the value.
// Assume that curr is pointing to a node
List-Delete(L, curr)
curr.next.prev = curr.prev
curr.prev.next = curr.next
curr.next = NIL
curr.prev = NIL
return curr
For a list with $n$ elements the following operations have the following time complexity:
Each table is one iteration:
| 34 | 10 | 64 | 51 | 32 | 21 |
|---|---|---|---|---|---|
| 10 | 34 | 64 | 51 | 32 | 21 |
| 10 | 34 | 64 | 51 | 32 | 21 |
| 10 | 34 | 51 | 64 | 32 | 21 |
| 10 | 34 | 51 | 32 | 64 | 21 |
| 10 | 34 | 51 | 32 | 21 | 64 |
| 10 | 34 | 32 | 21 | 51 | 64 |
| 10 | 32 | 21 | 34 | 51 | 64 |
| 10 | 21 | 32 | 34 | 51 | 64 |
| 10 | 21 | 32 | 34 | 51 | 64 |
No change, list is sorted.
Bold are being considered, italic are sorted.
for i = n downto 2 do
for j = 1 to (i - 1) do
if (A[j] > A[j + 1]) then
swap A[j] & A[j+1]
end
end
Generally you need a temporary variable, otherwise you will overwrite your original data:
tmp = x
x = y
y = tmp
You can also recover the data this way without using a temporary variable:
x += y
y = x - y
x -= y
This method is less readable and may overflow if you have two very large numbers.
The nested for loops give the following table:
| $i$ | N° of > Comparisons |
|---|---|
| $n$ | $n-1$ |
| $n-1$ | $n-2$ |
| $\vdots$ | $\vdots$ |
| 2 | 1 |
This gives the following simplified equation:
\[\frac{n^2-n}{2}\]We keep the highest power which gives the following big-O notation:
\[O(n^2)\]This time we will be looking at bubble sort in a linked list.
if head = NIL then
Empty list and STOP
last = NIL
curr = head
while curr.next =/= last do
begin
while curr.next =/= last do
begin
if curr.data > curr.next.data then
swapnode(curr, curr.next)
curr = curr.next
end
last = curr
curr = head
end
The time complexity is exactly the same as compared to using an array:
\[O(n^2)\]| 34 | 10 | 64 | 51 | 32 | 21 | To Swap |
|---|---|---|---|---|---|---|
| 34 | 10 | 64 | 51 | 32 | 21 | 34, 10 |
| 10 | 34 | 64 | 51 | 32 | 21 | 34, 21 |
| 10 | 21 | 64 | 51 | 32 | 34 | 64, 32 |
| 10 | 21 | 32 | 51 | 64 | 34 | 51, 34 |
| 10 | 21 | 32 | 34 | 64 | 51 | 64, 51 |
| 10 | 21 | 32 | 34 | 51 | 64 | |
| 10 | 21 | 32 | 34 | 51 | 64 |
Underlined is the current position, bold is the current smallest, and italic is sorted.
This will give the following code when using while loops:
i = 1
while i <= n do
begin
loc = i
j = i + 1
while j <= n do
begin
if A[j] < A[loc] then
loc = j
j++
end
swap A[i] and A[loc]
i++
end
and the following for for loops:
for i = 1 to (n - 1) do
begin
loc = i
for j = (i + 1) to n do
if A[j] < A[loc] then
loc = j
swap A[i] and A[loc]
end
The nested for loops give the following table:
| $i$ | N° of > Comparisons |
|---|---|
| $1$ | $n-1$ |
| $2$ | $n-2$ |
| $\vdots$ | $\vdots$ |
| $n-1$ | $1$ |
This gives the following simplified equation:
\[\frac{n^2-n}{2}\]We keep the highest power which gives the following big-O notation:
\[O(n^2)\]if head == NIL then
Empty list and STOP
curr = head
while curr.next =/= NIL do
begin
min = curr
node = curr.next
while node =/= NIL do
begin
if node.data < min dataq then
min = node
Node = node.next
end
swapnode(curr,min)
curr = curr.next
end
The time complexity is exactly the same as compared to using an array:
\[O(n^2)\]| 34 | 10 | 64 | 51 | 32 | 21 | Number shifted to right |
|---|---|---|---|---|---|---|
| 34 | 10 | 64 | 51 | 32 | 21 | |
| 10 | 34 | 64 | 51 | 32 | 21 | 34 |
| 10 | 34 | 64 | 51 | 32 | 21 | |
| 10 | 34 | 51 | 64 | 32 | 21 | 64 |
| 10 | 32 | 34 | 51 | 64 | 21 | 34, 51, 64 |
| 10 | 21 | 32 | 34 | 51 | 64 | 32, 34, 51, 64 |
Bold is the number being considered and italic is the sorted list.
for i = 2 to n do
begin
key = A[i]
loc = 1
while loc < i AND A[loc] < key do
loc++
for j = i downto (loc + 1) do
A[j] = A[j - 1]
A[loc] = key
end
The nested for loops give the following table:
| $i$ | N° of Comparisons | N° of Shifts |
|---|---|---|
| 1 | $\leq$ 1 | $\leq$ 1 |
| 2 | $\leq$ 2 | $\leq$ 2 |
| $\vdots$ | $\vdots$ | $\vdots$ |
| $n$ | $\leq n-$1 | $\leq n-$1 |
From this we get the following big-O notation:
\[O(n^2)\]head = NIL
while thereIsNewNumber do
begin
input number * create node
node.data = num
if head == NIL OR head.data > node.data then
begin
node.next = head
head = node
end
else begin
curr = head
while curr.next =/= NIL AND curr.next <= node.data do
curr = curr.next
node.next = curr.next
curr.next = node
end
end
The time complexity is exactly the same as compared to using an array:
\[O(n^2)\]Trees are linked lists with branches.
A tree $T=(V,E)$ consists of a set of vertices $V$ and a set of edges $E$ such that for any pair of vertices $u,v\in V$ there is exactly one path between $u$ and $v$:
graph TD
u((u)) --> y((y))
u --> v((v))
u --> x((x))
v --> w((w))
$T$ is connected and $m=n-1$ (where $n\equiv \vert V\vert,m\equiv \vert E\vert$).
This statement is proven next.
$P(n):$ If a tree $T$ has $n$ vertices and $m$ edges, then $m=n-1$.
By induction on the number of vertices.
A tree with single vertex does not have an edge.
graph TD
a(( ))
$n=1$ and $m=0$ therefore $m=n-1$
$P(n-1)\Rightarrow P(n)$ for $n>1$?
Remove an edge from the tree $T$. By (3), $T$ becomes disconnected. Two connected components $T_1$ and $T_2$ are obtained, neither contains a cycle (otherwise the cycle is also present in $T$.
graph LR
u((u)) ---|remove| v((v))
$u$ and $v$ are parts of two sub-trees ($T_1$ and $T_2$)that we are splitting.
Therefore, both $T_1$ and $T_2$ are trees.
Let $n_1$ and $n_2$ be the number of vertices in $T_1$ and $T_2$.
$\Rightarrow n_1+n_2=n$
By the induction hypothesis, $T_1$ and $T_2$ contains $n_1-1$ and $n_2-1$ edges, respectively.
Therefore we can calculate that $m=(n_1-1)+(n_2-1)+1$. Simplified this is $m=n_1+n_2-1$. As $n=n_1+n_2$ we can simplify to $m=n-1$.
Hence $T$ contains $(n_1-1)(n_2-1)+1=n-1$ edges.
This is a tree with a hierarchical structure such as a file structure:
graph TD
/ --- etc
/ --- bin
/ --- usr
/ --- home
usr --- ub[bin]
home --- staff
home --- students
students --- folder1
students --- folder2
folder1 --- file1
folder1 --- file2
folder1 --- file3
The degree of this tree is 4 as / has the largest degree.
There are three common ways to traverse a binary tree:
The difference is where the V appears.
For the following tree you would gain the following traversals:
graph TD
r --- a
r --- b
a --- c
a --- d
d --- g
b --- e
b --- f
f --- h
f --- k
r, a, c, d, g, b, e, f, h, k
You can imagine this as following the left of the node.
c, a, g, d, r, e, b, h, f, k
You can imagine this as following the middle of the node.
c, g, d, a, e, h, k, f, b, r
You can imagine this as following the right of the node.
For a vertex with value $X$:
graph TD
60 --- 40
60 --- 90
40 --- 20
40 --- 50
20 --- 10
20 --- 30
90 --- 80
90 --- 110
80 --- 70
110 --- 100
110 --- 120
To search for a number go left if you want to go smaller and right if you want to go bigger.
In-order traversal gives the tree in ascending order.
This tree represents a mathematical expression.
For the following expression:
\[(2+5*4)\times3\]In post-fix:
\[2\ 5\ 4 \times+\ 3\ \times\]graph TD
*1[*] --- +
*1 --- 3((3))
+ --- 2((2))
+ --- *2[*]
*2 --- 5((5))
*2 --- 4((4))
Post-order traversal will give the post-fix representation.
An undirected graph $G=(V,E)$ consists of a set of vertices $V$ and a set of edges $E$. Each edge is an unordered pair of vertices.
Unordered means that $\{b,c\}$ and $\{c,b\}$ refer to the same edge.
graph LR
a((a)) --- b((b))
a --- e((e))
a --- c((c))
a --- d((d))
b --- d
b --- c
b --- f
d --- e
e --- f
For the following graph:
graph LR
u((u)) --- w((w))
u --- x((x))
u ---|e| v((v))
w --- v
The degree of a vertex $v$, denoted by $\deg(v)$, is the number of edges incident with it.
A loop contributes twice to the degree.
The degree of a graph is the maximum degree over all vertices.
An undirected graph is simple if:
A directed graph $G(V,E)$ consists of the same as a directed graph. Each edge is an ordered pair of vertices.
Ordered means that the order of each pair of vertices refers to their direction.
graph LR
a((a)) --> b((b))
a --> e((e))
a --> c((c))
a --> d((d))
b --> d
b --> c
b --> f
d --> e
e --> f
This can be useful in referring to one-way paths.
Out-degree of a vertex $v$ - The number of edges leading away from $v$.
The sum of the in and out degrees should always be equal and the same as two times the number of edges.
There is an example on an undirected graph which proves:
The number of vertices with odd degree must be even.
An undirected graph ca be represented by an adjacency matrix, adjacency list, incidence matrix or incidence list.
Adjacency matrix $M$ for a simple undirected graph with $n$ vertices is an $n\times n$ matrix:
Adjacency list - each vertex has a list of vertices to which it is adjacent.
graph LR
a((a)) --- d((d))
a --- c((c))
b((b)) --- c
b --- d
c --- e((e))
c --- d
d --- e
The prior graph is represented in the following matrix:
\[\begin{pmatrix} 0 & 0 & 1 & 1 & 0\\ 0 & 0 & 1 & 1 & 0\\ 1 & 1 & 0 & 1 & 1\\ 1 & 1 & 1 & 0 & 1\\ 0 & 0 & 1 & 1 & 0 \end{pmatrix}\]$a$ to $b$ are listed left to right and top to bottom.
This can also be represented in this list:
The length of the list is the same as the number of edges.
If the graph has few edges and space is of a concern then the list is better.
Incidence matrix $M$ for a simple undirected graph with $n$ vertices and $m$ edges is an $m\times n$ matrix:
Incidence list - each edge has a list of vertices to which it is incident with.
graph LR
a((a)) ---|2| d((d))
a ---|1| c((c))
b((b)) ---|3| c
b ---|4| d
c ---|7| e((e))
c ---|5| d
d ---|6| e
The prior graph is represented in the following matrix:
\[\begin{pmatrix} 1 & 0 & 1 & 0 & 0\\ 1 & 0 & 0 & 1 & 0\\ 0 & 1 & 1 & 0 & 0\\ 0 & 1 & 0 & 1 & 0\\ 0 & 0 & 1 & 1 & 0\\ 0 & 0 & 0 & 1 & 1\\ 0 & 0 & 1 & 0 & 1 \end{pmatrix}\]Vertices $a$ to $b$ are left to right and edges 1 to 7 are top to bottom.
This can also be represented in this list:
Adjacency matrix $M$ for a simple directed graph with $n$ vertices is an $n\times n$ matrix:
Adjacency list - each vertex $u$ has a list of vertices pointed to by an edge leading away from $u$.
graph LR
a((a)) --> b((b))
c((c)) --> b
b --> d((d))
b --> e((e))
d --> e
c --> e
The prior graph is represented in the following matrix:
\[\begin{pmatrix} 0 & 1 & 0 & 0 & 0\\ 0 & 0 & 0 & 1 & 1\\ 0 & 1 & 0 & 0 & 1\\ 0 & 0 & 0 & 0 & 1\\ 0 & 0 & 0 & 0 & 0 \end{pmatrix}\]$a$ to $b$ are listed left to right and top to bottom.
This can also be represented in this list:
The length of the list is the same as the out-degree.
Incidence matrix $M$ for a directed graph with $n$ vertices and $m$ edges is an $m\times n$ matrix:
Incidence list - each vertex $u$ has a list of vertices pointed to by an edge leading away from $u$.
graph LR
a((a)) -->|1| b((b))
c((c)) -->|2| b
b -->|3| d((d))
b -->|4| e((e))
d -->|5| e
c -->|6| e
The prior graph is represented in the following matrix:
\[\begin{pmatrix} 1 & -1 & 0 & 0 & 0\\ 0 & -1 & 1 & 0 & 0\\ 0 & 1 & 0 & -1 & 0\\ 0 & 1 & 0 & 0 & -1\\ 0 & 0 & 0 & 1 & -1\\ 0 & 0 & 1 & 0 & -1 \end{pmatrix}\]Vertices $a$ to $b$ are left to right and edges 1 to 7 are top to bottom.
This can also be represented in this list:
The order is significant.
A circuit that visits every edge once.
Vertexes can be repeated.
Not all graphs have an Euler circuit.
Oppositely to an Euler circuit, this is a circuit that contains every vertex once.
This may not visit all edges.
This is a difficult problem to solve and will be reviewed later.
There are two main traversal algorithms: BFS and DFS. These have been covered in the following COMP111 lectures:
Suppose $a$ is the starting vertex:
graph LR
a((a)) --- b((b))
a --- e((e))
a --- d((d))
b --- f((f))
e --- f
d --- h((h))
f --- c((c))
e --- k((k))
e --- g((g))
f --- k
This would generate the following queues when searching with BFS:
Every time an element is removed from the queue, it is added to the traversal:
BFS: $a,b,d,e,f,h,g,k,c$
unmark all vertices
choose some starting vertex s
mark s and insert s into tail of list L
while L is non-empty do
begin
remove a vertex v from head of L
visit v // print its data
for each unmarked neighbour w of v do
mark w and insert w into tail of list L
end
Suppose $a$ is the starting vertex:
graph LR
a((a)) --- b((b))
a --- e((e))
a --- d((d))
b --- f((f))
e --- f
d --- h((h))
f --- c((c))
e --- k((k))
e --- g((g))
f --- k
This would generate the following stacks when searching with DFS:
$e,d,k\leftarrow \text{top}$
Not added to path as it already exists.
$e\leftarrow\text{top}$
Not added to path as it already exists.
Every time a unique element is popped from the stack, it is added to the traversal:
DFS: $a,b,f,c,e,g,k$
unmark all vertices
push starting vertex u onto top of stack S
while S is non-empty do
begin
pop a vertex v from top of S
if v is unmarked then
begin
visit and mark v
for each unmarked neighbour w of v do
push w onto top of S
end
end
The process of the greedy algorithm is explained in this lecture:
The main idea is to bin pack using the largest items first.
Greedy algorithm doesn’t always find an optimal solution but it is easy to implement.
You want to steal the best items from a house optimising for:
Formally this can be written like so:
Given $n$ items with weights $w_1,w_2,\ldots,w_n$, values $v_1,v_2,\ldots,v_n$ and a knapsack with capacity $W$.
Find the most valuable subset of items that can fit into the knapsack.
Approach:
Analysis:
Consider the following values:
One method of optimising would be to iterate through each combinations of subsets that fit in the knapsack and select the set with the most value:
| Subset | Weight | Value |
|---|---|---|
| $\emptyset$ | 0 | 0 |
| {1} | 10 | 60 |
| {2} | 20 | 100 |
| {3} | 30 | 120 |
| {1, 2} | 30 | 160 |
| {1, 3} | 40 | 180 |
| {2, 3} | 50 | 220 |
| {1, 2, 3} | 60 | N/A |
An issue with this method is that the combinations grow exponentially with additional items.
Consider the following values:
Pick the item with the next largest value if total weight $\leq$ capacity.
Result:
This happens to be optimal.
First the values need to be sorted. This takes:
\[O(n\log n)\]This algorithm doesn’t always give an optimal solution. Using other modifiers like $\frac v w$ also won’t give optimal solutions.
No matter the input, if a greedy algorithm has an approximation ratio of $\frac1 2$, it will always select a subset with a total value of at least $\frac 1 2$ of the optimal solution.
Given an undirected connected graph $G$:
Spanning tree of $G$:
A tree containing all vertices in $G$.
Minimum spanning tree of $G$:
Undirected connected graph $G$:
graph LR
a ---|2| b
b ---|3| c
a ---|3| c
b ---|2| d
c ---|1| d
graph LR
a ---|2| b
b ---|3| c
b ---|2| d
graph LR
a ---|2| b
b ---|2| d
c ---|1| d
graph LR
b ---|3| c
a ---|3| c
c ---|1| d
There are $m\choose{n-1}$ (choose) possible spanning trees, where $m$ is the number of edges in the original graph and $n$ is the number of nodes.
graph LR
a ---|2| b
b ---|2| d
c ---|1| d
This tree has the smallest total weight.
The idea is to select edges from smallest to largest weight until the MST is made.
graph LR
a ---|4| b
b ---|11| h
a ---|8| h
h ---|7| i
b ---|8| c
i ---|2| c
h ---|1| g
c ---|7| d
d ---|14| f
c ---|4| f
g ---|2| f
d ---|9| e
f ---|10| e
| ✓ | (g, h) | 1 |
|---|---|---|
| ✓ | (c, i) | 2 |
| ✓ | (f, g) | 2 |
| ✓ | (a, b) | 4 |
| ✓ | (c, f) | 4 |
| ✓ | (c, d) | 7 |
| Makes cycle | (h, i) | 7 |
| ✓ | (a, h) | 8 |
| Makes cycle | (b, c) | 8 |
| ✓ | (d, e) | 9 |
| Makes cycle | (e, f) | 10 |
| Makes cycle | (b, h) | 11 |
| Makes cycle | (d, f) | 14 |
This gives the following tree:
graph LR
a ---|4| b
a ---|8| h
i ---|2| c
h ---|1| g
c ---|7| d
c ---|4| f
g ---|2| f
d ---|9| e
Order of edges selected:
(g, h), (c, i), (f, g), (a, b), (c, f), (c, d), (a, h), (d, e)
This algorithm is greedy as it chooses the smallest wight edge to be included in the MST.
Given an undirected connected graph $G=(V,E)$:
T = Ø
E' = E // E' is the set of all edges
while E' != Ø do
begin
pick an edge e in E' with minimum weight
if adding e to T does not form cycle then
add e to T // This is the same as T = T ∪ {e}
remove e from E' // This is the same as E' = E' \ {e}
end
When we consider a new edge $e=(u, v)$, there may be three cases:
The time complexity is:
\[m(m+n)\]This will give a big-o notation of:
\[O(m^2)\]With these two the time complexity is:
\[O(m\log m)+O(mn)\]Consider a directed/undirected connected graph $G$:
Given a particular vertex called the source:
Undirected connected graph $G$:
graph LR
a ---|2| b
b ---|3| c
a ---|3| c
b ---|2| d
c ---|1| d
From $a$:
graph LR
a((a)) ---|2| b
a ---|3| c
b ---|2| d
From $b$:
graph LR
a ---|2| b
b((b)) ---|3| c
b ---|2| d
From $c$:
graph LR
b ---|3| c
a ---|3| c
c((c)) ---|1| d
From $d$:
graph LR
a ---|3| c
b ---|2| d((d))
c ---|1| d
This algorithm assumes that the weight of edges are positive.
The idea is to choose the edge adjacent to any chosen vertices such that the cost of the part to the source is minimum.
Suppose that $a$ is the source:
graph LR
a((a)) ---|5| b
a ---|7| c
b ---|10| h
c ---|2| h
c ---|7| e
e ---|5| h
e ---|5| f
f ---|1| h
c ---|2| d
a ---|10| d
d ---|4| e
f ---|3| g
d ---|3| g
h ---|2| g
graph LR
a((a)) ---|5| b["b: (∞, -)"]
a ---|7| c["c: (∞, -)"]
b ---|10| h["h: (∞, -)"]
c ---|2| h
c ---|7| e["e: (∞, -)"]
e ---|5| h
e ---|5| f["f: (∞, -)"]
f ---|1| h
c ---|2| d["d: (∞, -)"]
a ---|10| d
d ---|4| e
f ---|3| g["g: (∞, -)"]
d ---|3| g
h ---|2| g
graph LR
a((a)) ===|5| b["b: (5, a)"]
a -.-|7| c["c: (7, a)"]
b ---|10| h["h: (∞, -)"]
c ---|2| h
c ---|7| e["e: (∞, -)"]
e ---|5| h
e ---|5| f["f: (∞, -)"]
f ---|1| h
c ---|2| d["d: (10, a)"]
a -.-|10| d
d ---|4| e
f ---|3| g["g: (∞, -)"]
d ---|3| g
h ---|2| g
Followed paths are shown as dotted.
$a\rightarrow b$ has the minimum weight so is chosen in bold.
This continues until the following graph is reached:
graph LR
a((a)) ===|5| b["b: (5, a)"]
a ===|7| c["c: (7, a)"]
b -.-|10| h["h: (9, c)"]
c ===|2| h
c -.-|7| e["e: (13, d)"]
e -.-|5| h
e -.-|5| f["f: (10, h)"]
f ===|1| h
c ===|2| d["d: (9, c)"]
a -.-|10| d
d ===|4| e
f -.-|3| g["g: (11, h)"]
d -.-|3| g
h ===|2| g
You should record the history of label changes.
In the case of a tie there is no difference. You may want to go alphabetically.
| $b$ | $c$ | $d$ | $e$ | $f$ | $g$ | $h$ | Chosen |
|---|---|---|---|---|---|---|---|
| $(\infty,-)$ | $(\infty,-)$ | $(\infty,-)$ | $(\infty,-)$ | $(\infty,-)$ | $(\infty,-)$ | $(\infty,-)$ | $(\infty,-)$ |
| $(5,a)$ | $(7,a)$ | $(10,a)$ | $(\infty,-)$ | $(\infty,-)$ | $(\infty,-)$ | $(\infty,-)$ | $(a,b)$ |
| $(7,a)$ | $(10,a)$ | $(\infty,-)$ | $(\infty,-)$ | $(\infty,-)$ | $(15,b)$ | $(a,c)$ | |
| $(9,c)$ | $(14,c)$ | $(\infty,-)$ | $(\infty,-)$ | $(9,c)$ | $(c,d)$ | ||
| $(13,d)$ | $(\infty,-)$ | $(12,d)$ | $(9,c)$ | $(c,h)$ | |||
| $(13,d)$ | $(10,h)$ | $(11,h)$ | $(h,f)$ | ||||
| $(13,d)$ | $(11,h)$ | $(h,g)$ | |||||
| $(13,d)$ | $(d,e)$ |
Each vertex $v$ is labelled with two labels:
Given a graph $G=(V,E)$ and a source vertex $s$.
for every vertex v in the graph do
set d(v) = ∞ and p(v) = null
set d(s) = 0 and V_t = Ø and E_t = Ø
while V \ V_t != Ø do // there is still some vertex left
begin
choose the vertex v in V \ V_t with minimum d(u)
set V_t = V_t ∪ {u} and E_t = E_t ∪ {(p(u), u)}
for every vertex v in V \ V_t that is a neighbour of u do
if d(u) + w(u, v) < d(v) then // a shorter path is found
set d(v) = d(u) + w(u, v) and p(v) = v
end
$V_T$ and $E_T$ are the immediate sub-trees of $V$ and $V$ respectively.
The time complexity is:
\[v+n(n+n)\]This gives an overall big-o notation of:
\[O(n^2)\]The idea of divide and conquer is to divide a problem into several smaller instances of ideally the same size.
Find the sum of all the numbers in an array. Suppose we have 8 numbers:
\[\{4,6,3,2,8,7,5,1\}\]We can apply the following:
graph BT
1[4 6 3 2 8 7 5 1] -->|36| 0[ ]
10[4 6 3 2] -->|15| 1
11[8 7 5 1] -->|21| 1
100[4 6] -->|10| 10
101[3 2] -->|5| 10
1000[4] -->|4| 100
1001[6] -->|6| 100
1010[3] -->|3| 101
1011[2] -->|2| 101
110[8 7] -->|15| 11
111[5 1] -->|6| 11
1100[8] -->|8| 110
1101[7] -->|7| 110
1110[5] -->|5| 111
1111[1] -->|1| 111
For simplicity, assume that $n$ is a power of 2. We can then call the following algorithm by RecSum(A, 1, n):
Algorithm RecSum(A[], p, q)
if p == q then
return A[p] // this is the base case, there is one value
else
begin // this is the iterative step
sum1 = RecSum(A, p, (p+q-1)/2) // this finds the two sides of the midpoint
sum2 = RecSum(A, (p+q+1)/2, q)
return sum1 + sum2
end
This finds the minimum number in an array.
For simplicity, assume that $n$ is a power of 2. We can call the following algorithm by RecMin(A, 1, n):
Algorithm RecMin(A[], p, q)
if p == q then
return A[p] // pointing to the same value
else
begin
answer1 = RecMin(A, p, (p+q-1)/2) // divide the array
answer2 = RecMin(A, (p+q+1)/2, q)
if answer2 <= answer2 then // find minimum of returned values
return answer1
else
return answer2
end
The time complexity is:
\[O(n)\]This is as there are $n$ order 1 comparisons completed.
It is easier to merge two sequences that are already sorted, compared to two non-sorted sequences.
To merge two sorted sequences we keep two pointers, one to each sequence.
For simplicity, assume $n$ is a power of 2.
Algorithm Merge(B[1..p], C[1..q], A[1..(p+q)])
i = 1, j = 1, k = 1
while i <= p AND j <= q do
begin
if B[i] <= C[j] then // B is smaller
A[k] = B[i]
i++
else // C is smaller
A[k] = C[j]
j++
k++
end
if i == (p + 1) then // B is empty
copy C[j..q] to A[k..(p+q)]
else // C is empty
copy B[i..p] to A[k..(p+q)]
Consider the following variables:
The following iterations occur:
| i | j | k | A[] | |
|---|---|---|---|---|
| Before loop. | 1 | 1 | 1 | Empty |
| End of 1st iteration. | 1 | 2 | 2 | 5 |
| End of 2nd iteration. | 2 | 2 | 3 | 5, 10 |
| End of 3rd. | 3 | 2 | 4 | 5, 10, 13 |
| End of 4th. | 3 | 3 | 5 | 5, 10, 13, 21 |
| End of 5th. | 3 | 4 | 6 | 5, 10, 13, 21, 32 |
| End of 6th. | 3 | 5 | 7 | 5, 10, 13, 21, 32, 34 |
After if else. |
5, 10, 13, 21, 32, 34, 51, 64 |
This gives an overall time complexity of:
\[O(n\log n)\]This is faster than other algorithms that we have seen so far.
The formula for Fibonacci numbers is as follows:
\[F(n)=\begin{cases} 1 & \text{if } n=0 \text{ or } 1\\ F(n-1) + F(n-2) & \text{if } n> 1 \end{cases}\]This is a recursive implementation:
Algorithm F(n)
if n == 0 OR n == 1 then
return 1
else
return F(n-1) + F(n-2)
To analyse the time complexity of calculating Fibonacci numbers, we use a mathematical tool called recurrence.
Let $T(n)$ denote the time to calculate Fibonacci number $F(n)$:
\[T(n)=\begin{cases} 1 & \text{if } n=0 \text{ or } 1\\ T(n-1) + T(n-2) + 1 & \text{if } n> 1 \end{cases}\]A recurrence is an equation or inequality that describes a function in terms of its value on smaller inputs.
To solve a recurrence is to derive asymptotic bounds on the solution.
Suppose $n$ is even:
\[\begin{aligned} T(n) &= \mathbf{T(n-1)} + T(n-2) + 1\\ &= \mathbf{(T(n-2)+T(n-3)+1)} + T(n-2) + 1\\ &> 2\times T(n-2)\\ &> 2\times (\mathbf{2\times T(n-4)}) = 2^2 \times T(n-4)\\ &> 2^2\times (2\times T(n-6)) = 2^3 \times T(n-6)\\ &> 2^3\times (2\times T(n-8)) = 2^4 \times T(n-2\times 4)\\ &\vdots\\ &>2^k \times \mathbf{T(n-2k)}\\ &\vdots\\ &> 2^{\mathbf{\frac n 2}}\times \mathbf{T(0)}\\ &= 2^{\frac n 2} \end{aligned}\]Suppose $n$ is odd:
\[\begin{aligned} T(n) &> 2^{\mathbf{\frac{n-1} 2}} \times \mathbf{T(1)}\\ &=2^{\frac{n-1} 2} \end{aligned}\]The expressions being operated on are in bold.
\(T(n)=\begin{cases} 1 & \text{if } n= 1\\ 2\times T(\frac n 2)+n & \text{if } n> 1 \end{cases}\)
For the following recurrences, the following time complexities are true:
This is for finding sum/min/max.
This is merge sort.
This is Fibonacci numbers.
This is for recursive binary search.
Dynamic programming allows for more efficient implantation of divide and conquer algorithms.
This is the definition for the Fibonacci numbers:
\[F(n)=\begin{cases} 1 & \text{if } n=0\text{ or } 1\\ F(n-1)+F(n-2) & \text{if } n> 1 \end{cases}\]and the code that we had before:
Algorithm F(n)
if n == 0 OR n == 1 then
return 1
else
return F(n - 1) + F(n - 2)
This code calculates particular Fibonacci numbers many times which is inefficient.
To improve on this we can memorise new Fibonacci numbers so that we don’t have to calculate them again:
Main Algorithm
set v[0] = 1
set v[1] = 1
for i = 2 to n do
v[i] = -1 // initialise all other values to -1
output F(n)
Algorithm F(n)
if v[n] < 0 then
v[n] = F(n - 1) + F(n - 2)
return v[n]
This significantly reduces the amount of calculation.
The 2$^{nd}$ version still makes many function calls. Making many function calls negatively effects performance. To improve this we can compute the values from the bottom-up.
Algorithm F(n)
set v[0] = 1
set v[1] = 1
for i = 2 to n do
v[i] = v[i - 1] + v[v - 2]
return v[n]
Consider the following assembly line:
graph LR
subgraph Line1
11[5]
12[5]
13[9]
14[4]
end
subgraph Line2
21[15]
22[4]
23[3]
24[7]
end
Start --> 11
11 -->|0| 12
12 -->|0| 13
13 -->|0| 14
14 --> End
13 -->|1| 24
12 -->|4| 23
11 -->|2| 22
Start --> 21
21 -->|0| 22
22 -->|0| 23
23 -->|0| 24
24 --> End
23 -->|1| 14
22 -->|11| 13
21 -->|2| 12
Determine which stations to go in order to while minimising the total time through the $n$ stations.
You can represent all the possible paths in a tree structure:
You can then minimise for time while removing branches from the tree.
To avoid populating the entire tree you can use a dynamic programming approach. This is because we don’t need to try all the possible choices.
Definitions:
The final solution is:
\[\min\{f_1[n],f_2[n]\}\]Given $j$, what is the fastest way to get to $S_{1,j}$:
The fastest way to $S_{1,j-1}$, then directly to $S_{1,j}$:
\[f_1[j-1]+a_{1,j}\]The fastest way to $S_{2,j-1}$, a transfer from line 2 to line 1 then to $S_{1,j}$:
\[f_2[j-1]+t_{2,j-1}+a_{1,j}\]Therefore we want:
\[f_1[j]=\min\{f_1[j-1]+a_{1,j}, f_2[j-1]+t_{2,j-1}+a_{1,j}\}\]Boundary case:
\[f_1[1]=a_{1,1}\]Given $j$, what is the fastest way to get to $S_{2,j}$:
The fastest way to $S_{1,j-1}$, a transfer from line 2 to line 1 then to $S_{2,j}$:
\[f_1[j-1]+t_{1,j-1}+a_{2,j}\]The fastest way to $S_{2,j-1}$, then directly to $S_{2,j}$:
\[f_2[j-1]+a_{2,j}\]Therefore we want:
\[f_2[j]=\min\{f_2[j-1]+a_{2,j}, f_1[j-1]+t_{1,j-1}+a_{2,j}\}\]Boundary case:
\[f_2[1]=a_{2,1}\]For an example on two assembly lines view slide 15 onwards.
The summary is that you go from the beginning of the line to the end, keeping track of both sides, and choosing the least cost as you progress.
The expected table form would be like this:
| $j$ | $f_1[j]$ | $f_2[j]$ |
|---|---|---|
| 1 | 5 | 15 |
| 2 | 10 | 11 |
| 3 | 19 | 14 |
| 4 | 20 | 21 |
$f_1[j]$ and $f_2[j]$ are the shortest paths to each respective node.
f1[1] = a11
f2[1] = a21
for j = 2 to n do
begin
f1[j] = min{f1[j-1] + a1j, f2[j-1] + t2(j-1) + a1j}
f2[j] = min{f2[j-1] + a2j, f1[j-1] + t1(j-1) + a2j}
end
f* = min{f1[n], f2[n]}
The time complexity is:
\[O(n)\]as it loops through each node once and completes some $O(1)$ tasks.
For more assembly lines this time complexity is the same.