Vector spaces allow us to collect together vectors with similar characteristics.
Basics
We have $U$ - a set of $n$-vectors using $H$:
e.g. $U$ is the set of all 3-vectors from $\Bbb R$.
The set $U$ defines a vector space if it has two closure properties:
Adding any two vectors in $U$ produces a vector in $U$.
Multiplying any vector in $U$ by a constant in $H$ produces a vector in $U$.
Formal Definition
Given $U$ - a set of $n$-vectors using $H$. The set $U$ defines a vector space if:
\(\begin{align}
\forall v\in U, \forall w\in U &:v+w\in U &\text{(C1)}\\
\forall v\in U, \forall \alpha\in H &: \alpha v\in U &\text{(C2)}
\end{align}\)
Suppose $U$ is a vector space of $n$-vectors from $\Bbb R$. Important notions are a basis set and its dimension.
The idea of basis allows us to reduce $U$, even if it is infinite, to at most $n$ distinct vectors. We do this by expressing members of $U$ as linear combinations of other vectors in $U$.
Linear Combinations
Take a set $B$ of $m$ vectors from $U$:
\[B=\{t_1,t_2,\ldots,t_m\}\]
Take a collection $\vec a$ of $m$ values at least one of which is not 0 and all non-zero values are from $H$.
$\vec w$ is a linear combination of $B$ using $\vec a$ is $\vec w$ is:
\[\sum^m_{k=1}\alpha_kt_k\]
Linear Dependence & Independence
Now suppose that $U$ is a vector space and $B$ is a subset of $k$ $n$-vectors from $U$ for which any $w$ in $U$ can be obtained as a linear combination of $B$?
Linear transformation s map between vector spaces. When we use some method $T$ to produce a vector $\vec v$ in some vector space $V$ from a vector $\vec u$ belonging to a vector space $U$.
Formally:
\[T:U\rightarrow V\]
$U$ and $V$ can be the same vector space:
\[U=V=R^2\]
These may also be different vector spaces:
\[U=R^3,V=R^2\]
An example of this is projecting 3D object to 2D displays.
Why Are These Interesting?
Graphical Effects
Scaling an object, rotation may be implemented by matrix and vector multiplication.
I f an effect is a linear transformation then it is a matrix product.
If an effect is a matrix product then it is a linear transformation.
Matrices
A quick review of matrices was given. This included their anatomy and methods for multiplication.
Linear Transformation - Definition
Vector spaces $U$ and $V$ where $U$ may equal $V$.
$T$ a mapping from $U$ to $V$.
$T:V\rightarrow V$
$T$ is a linear transformation if:
$\forall p,q\in U:T(p+q)=T(p)+T(q)$
This means that if we take any two vectors ($p,q$) in the vector space $U$, if we add those two vectors and then apply the mapping $T$ then that should be the same as adding together the mapping on each individual vector.
The second condition is that if we take any constant value in the underlying set of numbers we are using to define the vectors, and we take any vector in the vector space; then the result of applying the transformation to the vector multiplied by the constant is the same as applying the transformation to the vector and multiplying the result by the constant.
Examples of 2D Effects
Scaling by a factor $s\in \Bbb R$
\(\pmatrix{s&0\\0&s}\pmatrix{x\\y}=\pmatrix{sx\\sy}=s\pmatrix{x\\y}\)
Rotating anti-clockwise around origin by $\theta^\circ$
This tutorial focuses on the answers for the first tutorial on numbers and polynomials.
Question 5
We are given the following numbers which can be expressed by the way of the following polynomials:
\(\begin{align}
1567\rightarrow p(x)=&x^3+5x^2+6x+7\\
3791\rightarrow q(x)=&3x^3+7x^2+9x+1
\end{align}\)
By multiplying them together we get the following polynomial:
\(\begin{align}
p\cdot q(x)=&3x^6+22x^5+62x^4+109x^3\\
&+108x^2+69x+7
\end{align}\)
The link between the set of digits and the set of numbers is such that each index relates to it’s place value.
Multiplying integers can be expressed in terms of finding the coefficients from the product of two polynomials.
As finding coefficients can be done quickly by exploiting properties of polynomial multiplication; this results in multiplication methods that are significantly faster than classical methods (grid method).
Question 6
This question is to prove that we can apply question 5 in any number base.
Converting between bases will increase the degree by a factor of their difference (base 6 to binary $=\text{degree}\times3$).
Summary
The purpose of these two questions is to show that you can complete multiplication via the use of polynomials. This will be advanced upon later in the way of showing an optimisation of multiplication for very large numbers.
You will generally be expected to find the euclidean distance.
This example will give:
\[\sqrt{25}=5\]
Spaces
Suppose you are given the following collection:
\[S=\{\langle p,q,r\rangle\in\Bbb Z ^3_8:p^q=q^r\}\]
Three vectors from the set of integers with modulo 8. When we take the first component and raise it to the power of the second modulo 8 we get the same as the second and third
\[H=\Bbb Z_8=\{0,1,2,3,4,5,6,7\}\]
$S$ is closed under scalar multiplication - False
$S$ is not closed under addition. - True
$S$ contains $\langle0,1,1\rangle$. - False
$S$ is a vector space. - False
$S$ does not contain $\langle1,1,0\rangle$. - False
Matrices
You can’t implement translation using a $2\times2$ vector. Scaling and rotation you can.
This was not explained. This is the reason that we can complete fast multiplication.
Fast Multiplication
Traditional methods to multiply two $n$ digit numbers, $X$ and $Y$, take each of the digits in $X$ and multiply each of the digits in $Y$.
This involves about $n^2$ basic operations.
Karatsuba’s Algorithm
graph TD
subgraph x
ab[A, B] --> ab2[A+B]
ab --> ac[A x C]
end
ab2 --> abcd["(A+B)x(C+D)"]
subgraph y
cd[C, D] --> cd2[C+D]
cd --> bd[DxD]
end
cd2 --> abcd
ac --> abcd2["(A+B)x(C+D)-(AxC)-(BxD)=(AxD)+(BxC)"]
bd --> abcd2
abcd --> abcd2
$A$ and $B$ are two equal length parts of the number $X$. The same is done for $Y$.
This method only uses three recursive calls and computes:
\[A\times C;B\times D;(A+B)(C+D)\]
The term $A\times D+B\times C$ needed is then just:
\[(A+B)(C+D)-A\times C-B\times D\]
The extra addition saves one call and the algorithm only needs $~n^{1.59}$ basic operations. This is much less than $n^2$
This method splits into two and exchanges multiplications for additions. By splitting more times then the additions add up and the effectiveness is reduced.
Schönhage-Strassen Algorithm
This method divides a $n$-digit numbers into roughly $\sqrt n$ parts each having $\sqrt n$ digits.
The convolution property allows the multiplication to be done quickly via the Fourier transform in $~n\log n$ steps.
Summary
The Fourier transform provides a powerful range of methods of importance in electronics and signal processing.
Its basis is in the complex analysis notion of primitive root.
In computer science one of the most significant applications was in its use to develop fast algorithms for multiplication.
Other uses include image compression.
Fast algorithms to compute the Fourier transform have also been developed.
So we have a function of two real variables mapping to two real-valued functions of two real variables.
This suggest applying partial derivatives.
Cauchy-Reimann Conditions
In order for $f’(z)$ to be sensibly defined bia partial derivatives we respect to $\text{Re}(z)$ and $\text{Im}(z)$ of $\text{Re}\left(f(z)\right)$ and $\text{Im}\left(f(z)\right)$ (the 2 variable functions $u(p,q)$ and $v(p,q)$ of the previous slide) there are some important preconditions that $u(p,q)$ and $v(p,q)$ have to satisfy.
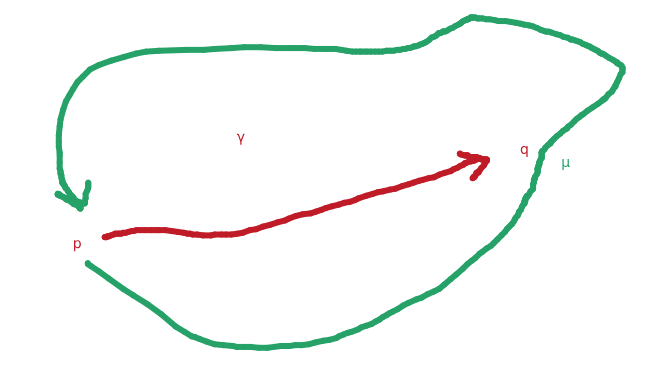
Two examples are given from slide 8 of the lecture slides.
This example is also run through from 10:29-16:24:
The first is for an open curve and the second is for a close curve.
Counting Objects
In computer science we might want to find exact or asymptotic estimates for the number of object of a particular type having size $n$.
Two tools that are often used are the notion of a generating function and a result called the (generalised) Cauchy integral formula.
Generating Function
Suppose we write:
\[G(z)=\sum^\infty_{n=0}a_nz^n\]
The coefficient of $z^n$ describes the number of interest.
We can often manipulate this sum to find a closed form.
Example
Consider counting the number of binary trees that have a certain number of leaves. We will use the above function as our generating function.
A binary tree is either a single root node ($n=0$) or a root node and two sub-trees, whose number of leaves added is $n$.
After some manipulation this allows $B(z)$ to be written as:
\[B(z)=\frac{1-\sqrt{1-4z}}{2z}\]
If we can find $z^n$ easily then we are done.
The Generalised Cauchy Integral Formula
If we want to find $a_n$ from a closed form (say $g(z)$ for $G(z)$ its generating function) we could differentiate $g(z)$ $n$ times and extract the value we need. Or, letting $g^{(n)}(z)$ denote this derivative:
We can use the generalised Cauchy integral theorem. Choose a closed contour $C$ then:
Pay attention to the dot product and the cross product.
Quaternion product is not commutative ($s\cdot t\neq t\cdot s$)
3D Graphics
Matrix-vector products don’t work well for rotation in 3D. Additionally they are computationally expensive.
Gimbal Lock
This phenomenon occurs when using matrix-vectors for 3D graphics. This is because you may ask for undefined values of trig functions. This will occur in errors.
Quaternions do not suffer from these errors.
Rotation with Quaternions
Suppose we are looking to rotate a point $(x,y,z)$ about some axis of rotation (an infinite line in 3D) $\vec v=\langle \alpha,\beta,\gamma\rangle$.
We wish to rotate through some angle $\theta^\circ$.
Choose the quaternion $q_\theta=[\cos(\frac{\theta}{2}),\sin(\frac{\theta}{2})\vec v]$
Since we are dealing with a line we can always choose $\vec v$ so that $q_\theta$ is a unit quaternion.
The computation “rotate $\vec w=\langle x,y,z\rangle$ by $\theta^\circ$ about $\vec v$” is just the quaternion product:
Let $f:\Bbb C\rightarrow \Bbb C$ be some complex valued function.
The $n^{\text{th}}$ iterate of $f$, denoted by $f_(n)$, when applied to $z\in\Bbb C$ is the complex number, denoted by $z_n$, that results by applying $f$ repeatedly (to the initial value $z_0$). Thus:
This is the method that we use to draw trends from experimental data. This is better than a table as it makes the data clearer.
Example
How to we best fit a line to this graph:
$x$
1.5
2.4
3.6
4.2
4.8
5.7
6.3
7.9
$y$
1.2
1.5
1.9
2.0
2.2
2.4
2.5
2.8
It seems that a curve would be best suited.
Least Squares
The standard interpretation of best fit is least squares.
We have data observation pairs:
\[\{\langle x_k,y_k\rangle:1\leq k\leq n\}\]
We want a function $F:\Bbb R\rightarrow \Bbb R$ that best describes these (minimises):
\[\sum^n_{k=1}(y_k-F(x_k))^2\]
This gives smaller values if the function fits the data better.
Linear Functions & Regression
This function is in the following form:
\[F(x)=ax+b\]
This means that finding the best line is finding the combination of $a$ and $b$ which results in the least squares sum.
Applying Least Squares
To minimise we would use the following function:
\[F(a,b)=\sum^n_{k=1}(y_k-ax_k-b)^2\]
Notice that the values $\{\langle x_k,y_k\rangle:1\leq k\leq n\}$ are constants.
To solve this we use partial differentiation, finding $\left(\frac{\partial F}{\partial a},\frac{\partial F}{\partial b}\right)$, and find the critical points for these.
Best Line Fit Function
From that we find that the best line fit function is:
These scalar values are called the eigenvalues of $A$.
The $n$-vectors $\vec x_\lambda$ are called the eigenvectors of $A$ (with respect to $\lambda$).
The case $\vec x = \vec 0$ always produces a solution. Theretofore, in finding eigenvectors, this case is not considered.
The case $\lambda = 0$ is of interest.
In general, finding eigenvalues involves fiding $\lambda$ for which:
\[(A-\lambda I)\vec x_\lambda = \vec 0\]
This is the same as finding:
\[\det(A-\lambda I)=0\]
Notice that $(A-\lambda I)$ is the matrix $A$ with $\lambda$ subtracted from each diagonal entry.
Solving via Polynomial Roots
The form $\det(A-\lambda I)=0$ has an interpretation involving roots of a polynomial.
Since $\det A$ (with some parameter $\lambda$) may be described as a polynomial of degree $n$ in $\lambda$ (with $A$ an $n\times n$ matrix) the solutions to $\det(A-\lambda I)=0$ are exactly the roots of this polynomial which is called the characteristic polynomial of $A$.
The characteristic polynomial of $A$ is denoted by: $\chi(A)$.
Consequences of Polynomial Similarity
An $n\times n$ matrix has $n$ eigenvalues (although these are not necessarily distinct).
This is similar to any other polynomial.
Eigenvalues may be complex numbers.
We won’t be studying these.
Matrices with all real eigenvalues include symmetric matrices:
It is often the case in applications that we don’t need all the eigenvalues for a given matrix.
We can check if a real matrix has a positive, real, largest eigenvalue using the Perron-Frobenius theorem.
These conditions also ensure existence of positive real eigenvectors for the associated eigenvalue.
This doesn’t check for dominant or uniqueness.
The Perron-Frobenius Conditions
If $A$ has only non-negative real elements and is irreducible:
There is unique positive real eigenvalue, $\lambda_{pf}$ associated with it.
Unique doesn’t imply dominant.
This eigenvalue has an eigenvector, $\vec x_{pf}$, that contains only positive real components.
Every other eigenvalue (including complex values) is such that $\vert\lambda\vert\leq\lambda_{pf}$.
The adjacency matrix of a strongly-connected directed graph is irreducible.
A directed graph is strongly-connected if there is a directed path from any node to any other node in the graph.
The Power Method
If $A$ has a dominant eigenvalue the power method allows an eigenvector associated with it to be found.
The method uses the fact that if $\vec x$ is an eigenvector of $\lambda$ of $A$ then for any constant $\alpha \in \Bbb R$, $a\vec x$ is also an eigenvector of $\lambda$.
Although the convergence to a dominant eigenvector is quick, the numbers involved in computing successive $\vec x_i$ become large so increasing computing time is needed.
This problem can be overcame using scaling. This adds the following step:
The transpose allows this to be calculated as a matrix by flipping the vector on it’s side.
This uses the dot product and reports the eigenvalue for $\vec x$. The dot product is calculated as so:
\[\vec x\cdot \vec y=\sum^n_{k=1}x_k\cdot y_k\]
Smallest Eigenvalue
We can find the smallest eigenvalue of $A$ is it is non-singular.
The smallest eigenvalue of $A$ is:
\[\frac 1 \lambda\]
where $\lambda$ is the largest eigenvalue of $A^{-1}$.
Spectral Graph Theory
The relationship between the spectra (adjacency matrices) of graphs and properties of the graphs themselves has been a long established study in algorithmics and computer science.
Usage Examples
The number of colours needed to properly colour the nodes of a graph so that no two linked nodes have the same colour is at most:
This relies on the fact that the sum of the $k^{th}$ powers of eigenvalues of an adjacency matrix divided by $k!$ reports the number of closed walks of length $k$ in the graph.
For $k\geq4$ we include degenerate cases as you are able to go back an forth between already visited edges.
An image can be represented as a matrix where each cell used 24 bits to encode the colour as RGB.
To compress it we can use the following method:
Given an $H\times W$ image $P$, let $M$ be the corresponding matrix.
$M$ will not typically be a square matrix.
Exploiting Spectra
Any $H\times W$ matrix $M$ can be described as the product of three matrices $U,S,V$:
$U$ is the same dimensions as the original matrix.
$S$ and $V$ are square matrices the same dimensions as $W$.
The original matrix can be recovered like so:
\[M=U\cdot S\cdot V\]
The Three Matrices
This method appears to use more space as shown below:
\[HW+W^2+W^2=W\cdot(H+2W)\]
The compression comes from removing rows and columns in $S$. As a result we have to remove the same:
Columns in $U$.
Rows in $V$.
This is to keep that matrix proportions.
Suppose we keep only $k$ rows and columns giving $S_k$. We end up with space:
\[k\cdot(H+k+W)< HW\]
This can be much smaller than $HW$.
Example
For an image with dimensions $2500\times2500$ requiring 18.75 Mb of space (using the RGB scheme). If it is the be encoded with SVD using a maximum of 3 Mb, what are the maximum dimensions for $S$.
Currently the SVD approach uses this much space:
\[3(2500^2+2500^2+2500^2)\approx56.25\text{Mb}\]
We can use the following equation from earlier to scale the image to fit a new size (the centre value is the matrix $S$):
\[3(2500k+k^2+2500k)\]
Solve this equation with respect to the required size:
\[3(2500k+k^2+2500k)=3\times10^6\]
This gives a $k$ value as $k=192$ as you round down to satisfy the size requirement.
Calculating $U,S$ and $V$
Given $M$, form the matrices:
\[\begin{aligned}
M&\cdot M^T\\
M^T&\cdot M
\end{aligned}\]
$M^T$ is the transpose of $M$.
These two matrices are square and symmetric. This means that: