Relational DB Quality - 1
Design Guidelines
Semantics of Attributes
Each relation should be a set of instances of a specific concept. This means that in a particular table that all attributes should be directly related.
Design relation schema so that it is easy to explain its meaning. Do not combine attributes from multiple entity types and relationship types into a single relation.
Redundancy
Redundancy generates anomalies:
- Insertion anomalies:
- When inserting a new lecturer, we have to know the Head of Department (or leave the field empty).
- Deletion anomalies:
- If all Computer Science lecturers are deleted, we lose information on who is the
HoDof Computer Science.
- If all Computer Science lecturers are deleted, we lose information on who is the
- Modification anomalies:
- If Computer Science changes
HoD, we need to update records for all Computer Science lecturers.
- If Computer Science changes
Design base relation schemas so that no update anomalies are present in the relations.
If any anomalies are present:
- Note them clearly.
- Make sure that the programs that update the database will operate correctly.
Null Values
If two concepts are grouped together, we can end up with many nulls. These give the issues of:
- Wasted storage space.
- No clear meaning.
- No
HoDforCompSci? Don’t know whetherCompScihas aHoD? Don’t know the name ofCompSciHoD?
- No
- Might create meaningless results.
- Might create wrong results.
- Say that you want to match entities in a certain group. If many entities have
nullas their group they will be matched but thisnullmay need different things for each one.
- Say that you want to match entities in a certain group. If many entities have
Avoid placing attributes in a base relation whose values may frequently be null.
If null is unavoidable:
- Make sure that they apply in exceptional cases only, not to a majority of tuples.
Spurious Records
If entities are not properly related then you can generate spurious records when joining their tables. This is an example:
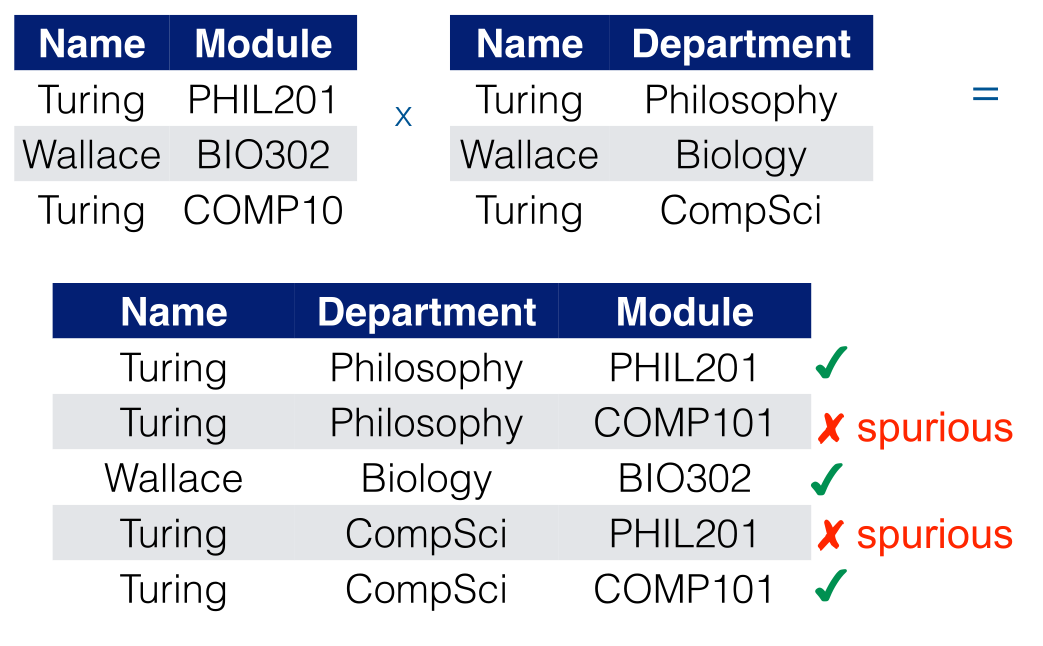
Design relation schemas to be joined with equality conditions on attributes that are appropriately related.
- Guarantees that no spurious tuples are generated.
- Avoid relations that contain matching attributes that are not “foreign key, primary key” combinations.
Summary
Most of the problems are due to a bad interpretation of the connections among attributes:
- If there is redundancy, or the semantics of a relation is convoluted then there must be some “forced” association of attributes in one relation which would better be decomposed.
- If there are many null values then it is not completely true that some attributes are a property of “every” instance of the relation.
- If one can create spurious tuples then there must be some connection among attributes that has not been recognised
This will be formalised in the next lecture on formalisation.